

Different AI platforms show different results because AI platforms generate answers using distinct models, training data, retrieval systems, and alignment policies. An AI platform in search and discovery refers to a system that retrieves information, interprets intent, and generates responses through artificial intelligence models and retrieval pipelines. These platforms combine language models, retrieval systems, contextual signals, and ranking algorithms to produce answers rather than simple link lists. Because each platform uses different architectures, datasets, and citation logic, the same query can produce different outputs across systems. These differences explain why AI-generated answers vary between platforms even when the question remains identical.
The reason different AI platforms show different results is primarily the set of inputs and signals used to generate each answer. AI answers depend on multiple inputs that shape the final output, including user prompts, conversation context, source data quality, NLP algorithms, model architecture, training data, few-shot examples, multimodal signals, system prompts, and retrieval systems, Retrieval-Augmented Generation. These inputs influence how the model interprets language, selects information, and generates text. The probabilistic nature of language models means responses are generated from probability distributions rather than fixed rules, which introduces variation between platforms. This mechanism explains why users often ask whether AI chatbots can make mistakes, and the answer is yes, because probabilistic generation occasionally produces incorrect or fabricated outputs.
Another reason different AI platforms show different results is the influence of freshness signals, personalization, and contextual interpretation. AI systems retrieve and prioritize information differently depending on whether the topic requires recent data or stable knowledge. Some platforms emphasize real-time web access and frequently updated content, while others rely more heavily on training data or curated sources. Contextual signals, user location, interaction history, and query framing further modify the output. These contextual signals personalize answers for individual users, meaning two people can receive different responses to the same question. Because responses are dynamic and context-aware, consistent tracking of visibility or brand mentions across AI systems becomes difficult.
AI hallucinations, platform variability, and measurement limitations further explain why AI platforms generate different results. An AI hallucination refers to a response where an AI model generates plausible but incorrect information, a known limitation of probabilistic generation systems. AI hallucinations occur when the model predicts language patterns without verified evidence, which is why users often ask what an AI hallucination is when evaluating AI reliability. Differences in model architecture, evaluation methodology, governance policies, and security frameworks influence how frequently hallucinations appear across platforms. These differences create operational, legal, and transparency risks and make AI visibility measurement inherently limited because AI answers are dynamic, private, and not indexed like search results. As a result, organizations comparing AI systems must rely on structured evaluation metrics and consistent testing methods rather than assuming identical behavior across platforms.
What Counts as an “AI Platform” in Search and Discovery?
An AI platform in search and discovery is a system that retrieves, interprets, and acts on information through artificial intelligence. An AI platform in search and discovery combines search, context analysis, answer generation, and task execution in one environment. This model moves beyond keyword matching because it connects information, intent, and action across systems.
What distinguishes AI platforms from AI-powered search and AI search? AI platforms differ from AI-powered search and AI search through deeper integration, stronger context handling, and direct outputs. AI-powered search improves traditional search relevance. AI search describes search functions that use artificial intelligence for better matching or answer generation. AI platforms combine retrieval, reasoning, synthesis, and action, so the system returns answers, insights, and next steps instead of only ranked results.
What technologies power AI platforms in search and discovery? There are 5 main technologies behind AI platforms in search and discovery. The technologies are listed below.
- Natural Language Processing (NLP) interprets language intent, context, and meaning. Natural Language Processing moves search beyond literal keyword matching. The language model layer reads phrasing, detects meaning, and maps the query to relevant information.
- Large Language Models (LLMs) generate answers, summaries, and rewritten outputs from large text datasets. Large Language Models process complex language patterns and organizational context. The model layer expands retrieval into synthesis and direct response generation.
- Retrieval-Augmented Generation (RAG) combines retrieved source material with generated output. Retrieval-Augmented Generation grounds answers in connected documents and authoritative data. The retrieval layer reduces unsupported output and increases source-based response quality.
- Machine Learning (ML) improves ranking and personalization from behavioral signals. Machine Learning uses clicks, session duration, cart additions, and shares to detect patterns. The learning layer refines relevance through repeated interaction with data.
- An Enterprise Graph links people, data, content, and processes into a connected knowledge model. An Enterprise Graph creates relationship awareness across systems. The graph layer improves context because the platform understands how entities connect inside the organization.
What are the core functions of an AI platform in search and discovery? An AI platform performs retrieval, answer generation, contextualization, conversation, and personalization in one system. The AI platform retrieves information through semantic analysis, vector search, and ranking methods. The AI platform then generates direct answers, summarizes source material, and adjusts outputs to permissions, recency, authority, and task context.
What makes AI platforms different from traditional search behavior? AI platforms prioritize semantic understanding, synthesized answers, and zero-click delivery over link-first result pages. The system reads meaning before it ranks content. The system cites sources through freshness, authority, readability, and entity consistency, which shifts visibility away from classic ranking signals alone.
What enterprise-specific capabilities define AI platforms? Enterprise AI platforms connect internal systems, analyze code, and automate cross-system work. Enterprise AI platforms integrate with SaaS applications and data repositories at scale. Enterprise AI platforms add code intelligence, in-app assistants, and agent workflows that execute multi-step tasks across repositories, documents, and business systems.
What examples show the breadth of AI platforms in search and discovery? AI platforms span consumer answer engines, generative engines, and enterprise search systems. The main categories include Generative Engine Optimization platforms (ChatGPT, Google Gemini, Perplexity, Claude), Answer Engine Optimization environments (Google AI Overviews, Bing Copilot), and enterprise AI search platforms (Glean, Moveworks, Coveo, Elastic, Guru). These examples show that AI platform coverage extends from public discovery to internal knowledge retrieval.
What properties define an AI platform in practical terms? An AI platform qualifies as an AI platform when it combines context-aware retrieval, generated answers, current information access, governance, and action-oriented workflows. The platform needs more than search enhancement. The platform needs connected data access, real-time or near-real-time indexing, permission-aware retrieval, summarization, credibility evaluation, and outputs that guide or complete work.
Why Do Differences Between AI Platforms Matter for Brands?
Differences between AI platforms matter for brands because AI platforms influence discovery, comparison, and decision processes before brand interaction occurs. AI platforms operate as discovery layers inside search engines, commerce ecosystems, and generative AI systems. These systems filter products, summarize information, and organize recommendations before a user reaches a brand website or advertisement.
What structural roles do AI platforms play in brand discovery? AI platforms operate through 2 primary discovery roles. The roles are listed below.
- AI as early decision-making layers inside platforms.
AI systems embedded inside commerce and search environments evaluate product attributes and behavioral signals. These systems compare options, summarize features, and guide product discovery inside platforms (Walmart, Amazon, OpenAI partnerships). - AI is the first contact point for consumer intent.
Generative AI systems function as the first research interface for many consumers. Consumers submit questions to systems (ChatGPT, Perplexity, Google AI Overviews, Amazon Rufus) for recommendations, comparisons, and evaluations before visiting retailers.
The operational differences between these roles appear in the comparison below.
| Feature / Aspect | AI as Early Decision-Making Layers | AI as First Contact for Consumer Intent |
|---|---|---|
| Primary Function | AI-driven interfaces compare options, summarize features, and guide product discovery inside platforms (Walmart, OpenAI partnership). | Consumers ask AI systems for advice, evaluations, and recommendations during the first stage of product exploration (ChatGPT, Perplexity, Google AI Overviews, Amazon Rufus). |
| Consumer Interaction Point | Integration occurs inside commerce, search, and content platforms before direct brand interaction. | Direct interaction occurs with generative AI tools before visiting retailer websites or search engines. |
| Impact on Brand Reach | AI systems influence purchase evaluation before a consumer reaches product pages or advertisements. | More than 60% of consumers conduct research through generative AI tools before retailer visits (McKinsey). |
| Content Prioritization | AI systems organize digital shelves using behavioral signals and product attributes. | AI systems prioritize content that aligns with CAAT principles (Credible, Authoritative, Authentic, Trusted). |
| Discovery Model | Discovery shifts toward Artificial Intelligence Optimization (AIO), where AI agents curate product options. | Discovery produces zero-click research journeys where answers appear without website navigation. |
| Traffic Impact | Organic discovery declines because product comparisons occur inside platform interfaces. | Click-through rates decline by up to 30% in several B2B software categories because AI summaries replace traditional results. |
| Brand Differentiation Challenge | Standardized AI comparison patterns reduce differentiation across similar product listings. | AI aggregation of industry best practices increases content similarity across competing brands. |
| Strategic Imperative | Brands structure product data and catalog attributes for AI comparison systems. | Brands publish authoritative multi-channel content that aligns with CAAT credibility signals. |
What impact do AI platforms have on traffic and visibility? AI platforms reduce traditional website traffic while increasing AI-mediated discovery. Approximately 60% of Google searches now end without a click because AI-generated answers deliver direct information. Early-stage organic discovery traffic declines between 15% and 25% across many industries.
What optimization strategies allow brands to adapt to AI platform differences? There are 2 primary optimization strategies for brands responding to AI platform differences. The strategies are listed below.
- Optimization for AI decision layers inside commerce and search platforms.
Firstly, brands structure product attributes and catalog data for AI comparison engines. Secondly, brands integrate product data with platform APIs and commerce systems. Thirdly, brands monitor AI-generated comparisons that influence purchase decisions. - Optimization for AI systems that capture early consumer research intent.
Firstly, brands publish authoritative, expert-driven content across multiple channels. Secondly, brands strengthen entity clarity and semantic structure across content assets. Thirdly, brands expand topical authority coverage to increase citation probability in AI-generated answers.
What financial impact results from AI platform optimization strategies? AI platform optimization increases marketing investment but strengthens early discovery influence. Optimization for platform decision layers increases content and data optimization costs by 15%-25% while improving on-platform conversion rates by 10%-15%. Optimization for generative AI discovery increases content production costs by 30%-50% while improving visibility inside AI-generated summaries by approximately 30%.
What decision criteria determine which strategy a brand prioritizes? Strategy selection depends on sales channels, discovery behavior, and marketing objectives.
What Inputs Shape an AI Answer?
Ten primary inputs shape an AI answer because AI systems generate responses from prompts, context, training data, and retrieval signals. An AI answer refers to the generated response produced by an artificial intelligence system after analyzing language input, contextual signals, and external knowledge sources. AI answers vary across platforms because each system processes prompts, data sources, and ranking logic differently.
What inputs shape how AI systems generate answers? There are 10 main inputs that shape an AI answer. The inputs are listed below.
- User Prompts and Query Framing
- Conversation Context and Persona
- Variability In Source Data and Quality
- NLP Algorithm Differences & Scoring
- Purpose-Driven & Domain-Specific Architecture
- Training Data and Fine-Tuning
- Few-Shot Examples and Prompt Conditioning
- Multimodal Input
- System Prompts and Alignment Policies
- External Knowledge Retrieval (RAG)
1. User Prompts and Query Framing
Why do user prompts and query framing shape an AI answer? User prompts and query framing shape an AI answer because prompts define the instruction, context, and constraints used by the AI system during response generation. A user prompt refers to the textual input submitted to an AI model that communicates the user’s request, intent, and expected output. Query framing refers to the structure, wording, and contextual signals included in the prompt that guide how the model interprets the task.
Why does prompt engineering change the quality of AI-generated answers? Prompt engineering changes AI output quality because prompt instructions shift the model output mode from conversational responses to structured knowledge responses. Prompt engineering refers to the process of structuring prompts to guide model reasoning, output format, and response depth. Structured prompts activate deeper knowledge patterns learned during training from books, research papers, and expert discussions.
Why does prompt framing influence response accuracy and relevance? Prompt framing influences response accuracy because framing reduces ambiguity in the user request. Query framing refers to the contextual description of the problem, audience, and objective within the prompt. Clear framing increases semantic precision and reduces misinterpretation during language processing.
What components define most AI prompts? Most AI prompts contain four core components that shape model interpretation. The components are listed below.
- A request defines the primary task the AI system must complete. The request component represents the core information needed, expressed in the prompt. A request example includes questions or tasks, identifying strategies, generating explanations, or evaluating options.
- Framing context provides situational information that explains the problem environment. Framing context describes the user’s goal, domain, or comparison criteria. Context signals guide the model toward domain-relevant reasoning and reduce vague responses.
- Format specification defines the required structure of the AI output. Format specification includes instructions about presentation, language level, length, and structure (bullet list, table, executive summary). Format constraints shape the structure of the generated response.
- References provide source material or examples that guide interpretation. References include internal references from previous responses or external references, copied text, or named documents. References reduce ambiguity by anchoring the request to known information.
Why do well-framed prompts produce better responses than vague prompts? Well-framed prompts produce better responses because structured prompts reduce ambiguity and increase semantic clarity. Vague prompts lack context, task specification, and format constraints. Ambiguity forces the model to infer missing details, which leads to generic or misaligned answers.
How does prompt structure influence AI output depth and organization? Prompt structure influences output depth because structured prompts define reasoning scope and response structure. Structured prompts include explicit instructions for explanation depth, output format, and reasoning requirements. These instructions guide the model toward longer and more organized responses.
How does context within a prompt influence answer quality? Prompt context improves answer quality because contextual signals align the response with a specific scenario or domain. Context embedding provides background information about the audience, environment, or use case. Context signals reduce generic answers and increase situational relevance.
What biases can appear in prompts and affect AI answers? Prompt wording can introduce bias because language framing influences model interpretation. Bias occurs when prompt phrasing steers the model toward a specific viewpoint or assumption. Bias effects appear in leading questions, example ordering, or imbalanced few-shot examples.
What common biases affect few-shot prompting? There are six common biases that appear in few-shot prompting. The biases are listed below.
- Majority label bias occurs when the model selects the most common label in examples. Example imbalance influences prediction distribution.
- Selection bias occurs when examples represent a narrow or unbalanced scenario. Non-representative examples distort model interpretation.
- Anchoring bias occurs when the first example determines response direction. Early examples create strong directional signals.
- Recency bias occurs when later examples influence predictions more strongly. The last example often receives greater weighting during interpretation.
- Formatting bias occurs when formatting differences influence prediction choice. Styling differences and bold labels alter attention patterns.
- Positional bias occurs when options at the start or end of a list appear more frequently in outputs. List order influences model selection patterns.
Why does prompt framing matter for business use of AI systems? Prompt framing matters for business use because structured prompts increase accuracy, efficiency, and operational reliability. Well-structured prompts reduce iteration cycles and increase response precision. Clear prompt design aligns AI output with business context, domain language, and organizational constraints.
2. Conversation Context and Persona
Why do conversation context and persona shape an AI answer? Conversation context and persona shape an AI answer because conversation context and persona define how the AI system interprets intent, tone, and response direction. Conversation context refers to the prior messages, instructions, references, and patterns inside the active exchange. Persona refers to the assigned role, voice, and behavioral frame that guides vocabulary, focus, and style.
Why does conversation context shape an AI answer? Conversation context shapes an AI answer because conversation context gives the model the pattern it continues. The model reads the full visible exchange as one input. The model then generates the next response from that full pattern, not from the latest message alone.
Why does persona shape an AI answer? Persona shapes an AI answer because persona defines role, tone, and point of view. Persona directs word choice, response style, and task focus. A precise persona creates tighter boundaries than a generic role label.
What does conversation context contain? Conversation context contains prior instructions, prior questions, prior answers, and prior references. These signals create response continuity across turns. These signals increase consistency because the model follows the strongest visible pattern.
What does persona contain? Persona contains role, communication style, behavioral rules, and task perspective. Role defines the position of the speaker. Communication style defines tone and vocabulary. Behavioral rules define what the model emphasizes or avoids. Task perspective defines the angle used in the answer.
Why do early messages matter so much in AI conversations? Early messages matter because early messages set the initial pattern for the rest of the exchange. This effect is often described as context gravity. A technical opening creates a technical pattern. A reflective opening creates a reflective pattern.
How do personas improve output quality in practical tasks? Personas improve output quality in practical tasks because personas reduce ambiguity and tighten response framing. A focused persona creates stronger boundaries for tone and focus. A focused persona often improves creative writing, training content, marketing copy, and editorial review.
What does persona design create stronger results? Strong persona design uses 4 main components. The components are listed below.
- Role defines who the model is in the task. A role example is a senior editor, a behavioral scientist, or a product marketer. The role sets authority and perspective.
- Context defines the situation around the task. Context explains the environment, audience, and objective. Context narrows the response path.
- The desired outcome defines what the answer must achieve. Desired outcome sets the success target. The desired outcome prevents vague output.
- Rules define hard boundaries for tone, structure, and behavior. Rules control what the model states, avoids, or prioritizes. Rules increase consistency across turns.
Why do vague personas produce weak results? Vague personas produce weak results because vague personas do not create useful boundaries. A prompt that says “act as an expert” gives little direction. A prompt that says “act as a senior pet physiotherapist explaining recovery steps to a new client” gives concrete direction.
What limits affect persona use? Persona use has clear limits because persona effectiveness changes by task type. Objective fact tasks often gain little from persona prompts. Creative, persuasive, and stylistic tasks often show stronger gains in tone consistency and engagement.
What risks appear when multiple personas mix in one conversation? Multiple personas create output instability because multiple personas introduce overlapping behavior patterns. This problem is often called persona bleed. Persona bleed fragments tone, creates contradictions, and weakens consistency.
How can prompts reduce persona bleed? Clear boundaries reduce persona bleed because clear boundaries separate one role from another role. Firstly, define one role with one task scope. Secondly, mark bounded sections with clear labels. Thirdly, reset the role before a new task begins.
Why does missing context create poor AI answers? Missing context creates poor AI answers because missing context forces the model to infer unstated details. The model fills gaps from general patterns instead of task-specific signals. This gap often produces generic answers, long exchanges, and repeated revisions.
What real structure appears in effective prompts with context and persona? Effective prompts with context and persona use 3 main layers. The layers are listed below.
- Framing states the problem and goal. Framing tells the model what situation it is handling. Framing reduces ambiguity.
- References anchor the answer to source material or prior text. References ground the response in visible material. References improve consistency.
- Format specification defines structure, tone, and length. Format specification shapes presentation and readability. Format specification reduces revision cycles.
Why do conversation context and persona matter for business use? Conversation context and persona matter for business use because conversation context and persona improve consistency, precision, and brand alignment. Strong context reduces wasted iterations. Strong persona keeps tone stable across assets, which improves editorial control and workflow efficiency.
3. Variability in Source Data and Quality
Why does variability in source data and quality shape an AI answer? Variability in source data and quality shapes an AI answer because variability in source data and quality determines what information the AI model learns, retrieves, and prioritizes. Source data refers to the datasets, documents, and knowledge sources used during model training or retrieval. Source data quality refers to the accuracy, coverage, reliability, and freshness of that information.
Why do AI systems generate different answers to the same question? AI systems generate different answers because AI systems use probabilistic token prediction instead of fixed rule selection. Probabilistic token prediction means the model predicts the next word from a probability distribution. The probability distribution reflects patterns learned from training data.
What mechanisms create variability in AI answers? There are 4 core mechanisms that create variability in AI answers. The mechanisms are listed below.
- Probabilistic token prediction creates multiple valid word sequences. The model selects the next token from several high-probability candidates. This selection produces different phrasing across responses.
- Sampling strategies influence token selection. Sampling methods choose tokens from a probability distribution rather than selecting the single highest probability token.
- Temperature settings control randomness during generation. Low temperature concentrates probability around the most likely tokens. High temperature spreads probability across a wider token range.
- Random seed initialization influences deterministic generation. The same random seed produces identical responses for identical prompts. Different seeds produce different outputs.
Why does training data variability affect AI answers? Training data variability affects AI answers because training data determines model knowledge patterns and ranking signals. Training data contains text patterns, facts, and language structures used during model training. These patterns influence how the model selects and organizes information.
What aspects define source data quality in AI systems? Source data quality depends on 5 main attributes. The attributes are listed below.
- Representativeness determines whether datasets reflect real-world scenarios.
Balanced datasets contain examples across demographics, domains, and edge cases. - Label accuracy determines whether training examples contain correct annotations. Incorrect labels introduce systematic errors during model learning.
- Completeness determines whether datasets cover the full range of possible scenarios. Missing edge cases produce brittle models that fail in unusual conditions.
- Consistency determines whether data collection and preprocessing follow stable standards. Inconsistent preprocessing introduces distortions and bias.
- Timeliness determines whether information reflects current conditions. Outdated data weakens performance in rapidly changing domains.
Why does poor data quality degrade AI performance? Poor data quality degrades AI performance because poor data quality introduces bias, inaccuracies, and unstable predictions. Biased datasets overrepresent certain perspectives. Inaccurate datasets introduce incorrect factual relationships. Incomplete datasets reduce model generalization.
Why does a large data volume not guarantee reliable AI answers? Large data volume does not guarantee reliable AI answers because information availability differs from information usability. AI systems reason only over the information available within the context window or retrieval layer. Missing or misaligned context produces incorrect conclusions.
Why do different AI platforms produce different answers from the same data? Different AI platforms produce different answers because AI platforms apply different retrieval, ranking, and synthesis strategies. Some systems rely primarily on learned patterns from training data. Other systems prioritize live retrieval from indexed sources.
What role does content freshness play in AI answer generation? Content freshness influences AI answers because newer information receives higher priority in certain retrieval systems. Retrieval systems rank recent documents more strongly for evolving topics. Historical sources dominate answers when freshness signals remain weak.
How does brand information variability affect brand visibility in AI answers? Brand information variability affects brand visibility because fragmented brand signals reduce entity clarity. Clear brand signals include consistent naming, repeated entity references, and claims validated across trusted sources. Strong entity signals increase stable inclusion in AI answers.
What strategies reduce variability caused by weak or inconsistent data? There are 4 main strategies that reduce variability caused by weak or inconsistent data. The strategies are listed below.
- Prioritize high-quality data preparation. Data cleaning, preprocessing, and label validation increase model reliability.
- Increase data representativeness. Balanced datasets improve performance across diverse scenarios.
- Monitor model drift through continuous evaluation. Monitoring identifies performance degradation caused by data changes.
- Reinforce entity signals across trusted sources. Consistent entity descriptions increase stable retrieval in AI answers.
4. NLP Algorithm Differences and Scoring
NLP algorithm differences and scoring shape an AI answer because NLP algorithms determine how language input is interpreted, ranked, and transformed into responses. Natural Language Processing (NLP) refers to the artificial intelligence field that enables machines to process human language. Natural Language Processing algorithms analyze text structure, meaning, and relationships to produce responses.
Why do NLP algorithms influence AI interpretation of language? NLP algorithms influence AI interpretation of language because NLP algorithms analyze syntax, semantics, and context within human communication. Syntax analysis examines grammatical structure and word order. Semantic analysis evaluates meaning and intent within the sentence.
What computational methods allow NLP algorithms to interpret language? There are 4 computational methods that allow NLP algorithms to interpret language. The methods are listed below.
- Statistical modeling analyzes language patterns using probability distributions.
Statistical models evaluate how frequently words appear together in training data. - Machine learning detects patterns from labeled or unlabeled language data.
Machine learning algorithms train on datasets to recognize linguistic structures. - Deep learning processes language through neural network architectures.
Neural networks model relationships between tokens through layered computation. - Computational linguistics analyzes grammatical and semantic structure.
Computational linguistics studies language rules, sentence structure, and meaning relationships.
Why does the choice of a NLP algorithm affect AI answers? The choice of a NLP algorithm affects AI answers because different algorithms interpret language signals differently. Some algorithms prioritize statistical patterns. Other algorithms prioritize symbolic relationships or contextual reasoning.
What core NLP tasks allow AI systems to process language input? There are 4 core NLP tasks that allow AI systems to process language input. The tasks are listed below.
- Tagging identifies grammatical roles within a sentence. Tagging assigns labels to tokens (noun, verb, adjective, preposition).
- Parsing organizes sentence structure into hierarchical relationships. Parsing builds grammatical trees that show phrase relationships.
- Named Entity Recognition identifies real-world entities in text. Named Entity Recognition detects people, organizations, locations, and other entities.
- Relation extraction identifies relationships between detected entities. Relation extraction determines connections between entities through contextual signals.
What preprocessing steps prepare text for NLP analysis? NLP preprocessing prepares language data before algorithmic analysis begins. Preprocessing converts raw text into structured tokens and linguistic features.
There are 5 main preprocessing steps. The steps are listed below.
- Tokenization splits sentences into individual tokens. Tokenization separates words and punctuation into analyzable units.
- Stop-word removal removes extremely common words with limited semantic value. Stop-word filtering reduces noise in statistical analysis.
- Lemmatization converts words to their base linguistic form. Lemmatization normalizes variations of the same word.
- Part-of-speech tagging assigns grammatical categories to tokens. Part-of-speech tagging improves contextual interpretation.
- Named entity tagging labels recognized entities within text. Entity tagging identifies structured knowledge elements.
What common NLP algorithms generate language understanding tasks? Several NLP algorithms perform specialized language analysis tasks.
| Algorithm | Core Function | Common Applications |
|---|---|---|
| Sentiment Analysis | Determines sentiment polarity in text. | Customer sentiment analysis, marketing analysis, and social media monitoring. |
| Named Entity Recognition (NER) | Identifies entities within text. | Information extraction, search indexing, content categorization. |
| Text Summarization | Generates shorter versions of documents. | Document review, knowledge retrieval, and information summarization. |
| Aspect Mining | Detects product or topic attributes within text. | Customer feedback analysis, conversational AI systems. |
| Statistical Language Modeling | Predicts the next token based on prior tokens. | Autocomplete systems, speech recognition systems. |
| Machine Translation | Converts text between languages. | Cross-language communication, multilingual question answering. |
What major categories of NLP algorithms exist? NLP algorithms fall into 3 main categories. The categories are listed below.
- Statistical algorithms learn language patterns through probability distributions.
Statistical NLP processes large text datasets to detect language patterns. - Symbolic algorithms analyze logical relationships between words and concepts.
Symbolic NLP uses rule systems and linguistic knowledge structures. - Hybrid algorithms combine statistical learning and symbolic reasoning.
Hybrid systems integrate pattern recognition with rule-based interpretation.
How do deep learning models improve NLP performance? Deep learning improves NLP performance because neural architectures model complex relationships between tokens. Neural architectures capture contextual dependencies across long text sequences.
There are 3 major neural architectures used in modern NLP. The architectures are listed below.
- Convolutional Neural Networks analyze patterns in structured input data.
Convolutional Neural Networks process image, audio, and text features. - Recurrent Neural Networks process sequential data streams.
Recurrent Neural Networks track token dependencies across time. - Transformer architectures model global token relationships using attention mechanisms.
Transformer models evaluate token relationships across the entire sequence simultaneously.
What evaluation metrics measure NLP system performance? NLP scoring metrics evaluate how accurately an NLP system processes language tasks.
| Metric | Application | Example Performance |
|---|---|---|
| BLEU | Machine translation evaluation. | Transformer models achieved 28.4 BLEU on WMT-14 English-German benchmarks. |
| F1 Score | Classification and tagging tasks. | Combines precision and recall into a balanced score. |
| Perplexity | Language modeling evaluation. | Measures how well a probability distribution predicts token sequences. |
| User Satisfaction | Conversational AI evaluation. | Measures perceived usefulness and response quality. |
Why do NLP algorithm differences cause different AI answers across platforms? NLP algorithm differences cause different AI answers because each platform applies different interpretation, ranking, and evaluation systems. Platform-specific NLP pipelines determine entity recognition, intent classification, and answer ranking.
What challenges limit NLP algorithm accuracy? NLP algorithms face several technical challenges that influence answer reliability.
There are 5 major challenges. The challenges are listed below.
- Ambiguity complicates the interpretation of words with multiple meanings.
Language ambiguity appears in metaphors, slang, and cultural references. - Bias emerges from imbalanced training datasets.
Dataset bias can introduce unfair or skewed predictions. - Translation complexity arises from structural differences between languages.
Language grammar differences complicate cross-language conversion. - Model interpretability decreases as neural model complexity increases.
Large models make internal reasoning difficult to trace. - High computational requirements increase infrastructure demands.
Large NLP models require specialized hardware and large-scale compute resources.
5. Purpose-Driven and Domain-Specific Architecture
Why does purpose-driven and domain-specific architecture shape an AI answer? Purpose-driven and domain-specific architecture shape an AI answer because purpose-driven and domain-specific architecture determine what tasks the AI system prioritizes and how knowledge is structured. Purpose-driven architecture refers to system design optimized for a specific task or workflow. Domain-specific architecture refers to system design optimized for a specific knowledge domain or operational environment.
Why do AI systems require purpose-driven architectures? AI systems require purpose-driven architectures because general-purpose architectures introduce inefficiency for specialized tasks. General-purpose systems attempt to cover many tasks with one model. Specialized architectures remove unnecessary computation and improve performance for targeted tasks.
Why do domain-specific models produce more reliable answers in specialized fields? Domain-specific models produce more reliable answers because they train on curated datasets from one knowledge domain. Domain-specific models process domain terminology, workflows, and constraints with greater accuracy. General-purpose models rely on broad datasets that lack deep domain structure.
What defines a domain-specific AI model? A domain-specific AI model is an artificial intelligence system trained or fine-tuned for a single domain or application area. Domain-specific AI models use curated datasets from fields (medicine, law, or finance). Domain-specific training improves accuracy and contextual reasoning within the target field.
What benefits arise from domain-specific AI models? Domain-specific AI models provide multiple operational benefits in specialized environments.
| Benefit | Description | Quantitative Impact |
|---|---|---|
| Depth and Accuracy | Domain datasets provide a deeper contextual understanding of specialized knowledge. | Higher accuracy for domain-specific questions and analysis. |
| Reduced Hallucinations | Domain knowledge bases constrain the model to verified information patterns. | Lower frequency of incorrect or fabricated responses. |
| Faster Training and Lower Compute | Domain vocabulary and workflows narrow the training scope. | Reduced computational cost during model training. |
| Higher Efficiency | Architecture optimization removes unnecessary general-purpose capabilities. | Improved performance per dollar and energy efficiency. |
| Higher Interpretability | Domain knowledge aligns with structured expert understanding. | Easier validation and regulatory review. |
Why do hardware architectures influence AI answer generation? Hardware architectures influence AI answer generation because hardware architectures determine computational efficiency and memory throughput. Large AI models require massive memory transfers during inference. Efficient hardware architectures reduce data movement and energy consumption.
Why does memory represent the main constraint in AI inference? Memory represents the main constraint in AI inference because memory operations consume the majority of system energy. Reading and writing from DRAM requires significantly more energy than arithmetic computation. Efficient architectures minimize memory movement to improve system efficiency.
What properties define optimized domain-specific architectures for AI inference? There are 5 main properties that define optimized domain-specific architectures. The properties are listed below.
- Low-precision data type support reduces computational workload. Lower precision representations reduce tensor size and arithmetic complexity.
- Asynchronous memory transfers overlap computation and data movement. Compute units perform operations while data transfers occur in parallel.
- Dedicated tensor memory transfer hardware accelerates data movement. Direct memory access subsystems move tensors without CPU involvement.
- Large scratchpad memory replaces traditional cache hierarchies. Scratchpad memory provides faster and more predictable data access.
- High memory bandwidth increases inference throughput. High bandwidth supports faster processing of large neural network tensors.
Why do large AI models scale across multiple accelerators? Large AI models scale across multiple accelerators because model parameters exceed the memory capacity of a single device. Distributed inference splits model components across hardware units. Communication bandwidth becomes critical in multi-accelerator environments.
What architecture stack enables domain-specific AI applications? There are 3 layers in the Domain Agent Stack architecture. The layers are listed below.
- DSLM Foundation provides domain-trained language models. Domain-Specific Language Models (DSLMs) store domain knowledge and reasoning patterns.
- RAG layer retrieves current information from external knowledge sources. Retrieval-Augmented Generation connects the model to external documents and databases.
- Agentic layer orchestrates tasks and decision workflows. Agent systems coordinate multiple tools, models, and retrieval processes.
Why does domain-driven design improve AI system architecture? Domain-driven design improves AI architecture because it aligns system structure with domain logic and business objectives. Domain-driven design organizes complex systems around domain boundaries and responsibilities.
What architectural patterns exist for multi-agent AI systems? There are 4 orchestration patterns for multi-agent AI systems. The patterns are listed below.
- Sequential orchestration executes agents in a fixed pipeline order.
Each agent processes output from the previous step. - Concurrent orchestration runs agents in parallel for the same task.
Results from multiple agents combine after parallel processing. - Group collaboration orchestration creates shared interaction among agents and humans.
Agents exchange information within a shared conversation environment. - Manager orchestration coordinates agents through a central planning agent.
The manager agent assigns subtasks and selects specialized agents.
Why do domain-specific architectures create competitive advantages? Domain-specific architectures create competitive advantages because they improve accuracy, efficiency, and reliability within targeted problem spaces. Specialized architecture reduces operational cost while increasing response precision. Organizations deploy domain-specific AI systems to deliver consistent results in regulated or knowledge-intensive industries.
6. Training Data and Fine-Tuning
Why training data and fine-tune shape an AI answer? Training data and fine-tuning shape an AI answer because training data and fine-tuning determine the knowledge patterns and behavioral adjustments of the model. Training data refers to the datasets used to train a foundation model. Fine-tuning refers to the process of adapting a trained model to a specific domain or task.
Why does training data shape AI answers? Training data shapes AI answers because training data defines the language patterns and knowledge learned by the model. Training datasets contain billions of tokens from text, documents, and multimodal content. These datasets establish the statistical relationships the model uses during response generation.
What role do foundation models play in AI answer generation? Foundation models shape AI answers because foundation models provide the general knowledge base used during inference. Foundation models train on large datasets from across the open internet and public sources. This training enables models to recognize language patterns, entities, and concepts across many domains.
How does fine-tuning change AI model behavior? Fine-tuning changes the AI model’s behavior because fine-tuning adjusts model parameters using task-specific datasets. Fine-tuning datasets contain smaller collections of labeled examples from a defined domain. These datasets teach the model specialized terminology, taxonomy, and contextual rules.
What differences exist between fine-tuning and training from scratch? Fine-tuning and training from scratch differ in dataset size, computational cost, and development time.
| Data Requirement | Fine-Tuning | Training from Scratch |
|---|---|---|
| Dataset Size | Hundreds or thousands of labeled examples. | Millions or billions of training examples. |
| Computational Cost | Hours or days of training with moderate computing requirements. | Months of training with large-scale GPU or TPU clusters. |
| Data Quality | Small high-quality datasets with domain relevance. | Massive labeled datasets required for generalization. |
Why does data quality matter during fine-tuning? Data quality matters during fine-tuning because fine-tuning datasets directly shape domain knowledge inside the model. High-quality labeled datasets produce more reliable outputs. Poor-quality datasets introduce incorrect patterns and reduce model accuracy.
What data preparation steps occur before fine-tuning? There are 4 main preparation steps before fine-tuning begins. The steps are listed below.
- Clean training samples to remove corrupted or irrelevant records.
Data cleaning ensures consistent and accurate training signals. - Preprocess text to match the expected format of the base model.
Preprocessing converts raw text into tokenized input sequences. - Label examples according to the target task objective.
Labeling defines the correct output associated with each training input. - Split the dataset into training and validation sets.
Dataset splitting enables model evaluation during training.
Why does fine-tuning improve performance efficiency? Fine-tuning improves performance efficiency because fine-tuning reuses the general knowledge of foundation models. Foundation knowledge reduces the need for large-scale training. Fine-tuning requires fewer training iterations and lower compute resources.
What risks exist when fine-tuning AI models? Fine-tuning introduces several risks that affect model reliability. There are 3 main risks. The risks are listed below.
- Overfitting occurs when the model adapts too strongly to a small dataset. Overfitting reduces the model’s ability to generalize to unseen inputs.
- Knowledge override occurs when domain training replaces useful general knowledge. Excessive training iterations reinforce narrow patterns.
- Dataset mismatch occurs when fine-tuning data conflicts with the original training data. Dataset mismatch creates inconsistent model responses.
Why does training from scratch require large resources? Training from scratch requires large resources because training from scratch builds the entire knowledge base without pre-trained weights. This process requires massive datasets, large compute clusters, and extensive training time.
What alternatives exist to inject knowledge without fine-tuning? There are 4 main alternatives to inject knowledge without fine-tuning. The approaches are listed below.
- Embeddings connect model responses to external knowledge vectors. Embeddings map text content into a vector space for similarity retrieval.
- Retrieval-Augmented Generation retrieves documents during answer generation. RAG systems combine model reasoning with external knowledge sources.
- System prompt instruction sets define behavioral rules for responses. System prompts guide reasoning and output structure.
- Prompt engineering structures instructions to guide model reasoning. Prompt design influences task interpretation and response format.
Why do training data and fine-tuning matter for AI platform differences? Training data and fine-tuning matter for AI platform differences because training data and fine-tuning determine model knowledge boundaries and domain specialization. Different platforms train on different datasets and apply different fine-tuning strategies. These differences produce variation in knowledge coverage, tone, and reasoning patterns across AI systems.
7. Few-Shot Examples and Prompt Conditioning
Why do few-shot examples and prompt conditioning shape an AI’s answer? Few-shot examples and prompt conditioning shape an AI answer because few-shot examples and prompt conditioning guide how the AI model interprets tasks and formats responses. Few-shot examples refer to sample inputs and outputs placed inside a prompt. Prompt conditioning refers to instructions and patterns that steer how the model generates responses.
Why do few-shot examples influence AI output behavior? Few-shot examples influence AI output behavior because they demonstrate the expected reasoning pattern and answer format. The model observes the structure of the examples and replicates that structure in new responses. The examples act as behavioral templates for the generation process.
What does few-shot prompting mean in AI systems? Few-shot prompting is a prompting method that includes several labeled examples before the final query. Each example contains an input and a corresponding output. These examples establish the reasoning style and formatting pattern for the response.
How do few-shot examples shape reasoning patterns? Few-shot examples shape reasoning patterns because few-shot examples anchor the model to specific logical structures. Example ordering, label distribution, and formatting signals influence prediction patterns. These signals guide how the model selects tokens during generation.
What biases appear in few-shot prompting? There are 6 common biases that appear in few-shot prompting. The biases are listed below.
- Majority label bias occurs when examples contain more instances of one label.
The model predicts the most frequent label in the example set. - Selection bias occurs when examples represent a narrow scenario.
Non-representative examples distort the predicted outcome. - Anchoring bias occurs when the first example strongly influences interpretation.
Early examples guide the reasoning direction. - Recency bias occurs when later examples receive stronger weighting.
Recent examples influence prediction more than earlier examples. - Formatting bias occurs when formatting signals influence prediction choice.
Bold text, punctuation, or layout patterns alter token attention. - Positional bias occurs when items at list boundaries appear more frequently in predictions.
Options at the beginning or end of lists receive a higher probability.
What is prompt conditioning in AI systems? Prompt conditioning is a prompting technique that uses structured instructions to control model behavior. Prompt conditioning defines role, tone, task objective, and output constraints. These instructions shape the response generation process.
What elements create effective prompt conditioning? There are 5 elements that create effective prompt conditioning. The elements are listed below.
- Role definition establishes the perspective used in the response. Role definition assigns the model a specific identity or expertise.
- Task definition specifies the objective of the response. Task definition clarifies the action required from the model.
- Context embedding supplies relevant background information. Context embedding aligns the response with the situation.
- Output format constraints define structure and presentation. Format constraints control lists, tables, summaries, or explanations.
- Instruction rules establish boundaries for tone and content. Instruction rules restrict unwanted behavior and guide style.
Why do few-shot examples improve output consistency? Few-shot examples improve output consistency because they reduce ambiguity during task interpretation. Clear examples narrow the range of possible responses. Narrow response ranges increase consistency across multiple generations.
How does prompt conditioning affect AI reasoning quality? Prompt conditioning affects AI reasoning quality because prompt conditioning organizes the reasoning path before generation begins. Structured instructions guide the model toward relevant reasoning steps. Structured reasoning instructions reduce generic or unfocused answers.
Why do few-shot examples and prompt conditioning matter for AI platform differences? Few-shot examples and prompt conditioning matter for AI platform differences because platforms use different prompting strategies and internal instruction layers. Internal system prompts, role instructions, and example templates differ across AI systems. These differences produce variation in reasoning structure, tone, and output format.
8. Multimodal Input
Why multimodal input shapes an AI answer? Multimodal input shapes an AI answer because multimodal input provides multiple data types that influence how the AI system interprets context and meaning. Multimodal input refers to input signals that combine different media types within a single interaction. Multimodal input includes text, images, audio, and video signals processed together.
Why do multimodal inputs influence AI interpretation? Multimodal inputs influence AI interpretation because multimodal inputs expand the contextual signals available during analysis. Text alone provides linguistic signals. Images, audio, and visual context add spatial, emotional, and environmental signals.
What types of inputs exist in multimodal AI systems? There are 4 main input types used in multimodal AI systems. The input types are listed below.
- Text input represents written language instructions or questions. Text input provides explicit semantic meaning and structured queries.
- Image input represents visual content captured in pictures or screenshots. Image input contains objects, scenes, symbols, and spatial relationships.
- Audio input represents spoken language or environmental sound. Audio input captures tone, pronunciation, and acoustic context.
- Video input represents sequences of visual frames over time. Video input captures motion, actions, and temporal relationships.
Why does combining multiple input types improve AI understanding? Combining multiple input types improves AI understanding because multimodal systems correlate signals across different data representations. Visual signals clarify objects or scenes referenced in text. Audio signals clarify tone or spoken intent.
How do multimodal AI models process different input types? Multimodal AI models process different input types through modality-specific encoders. Each encoder converts input signals into vector embeddings. The embeddings align in a shared representation space for joint reasoning.
What model architectures enable multimodal processing? There are 3 main architectural components used in multimodal AI systems. The components are listed below.
- Vision encoders convert images into numerical feature representations. Vision encoders detect objects, shapes, and spatial relationships.
- Audio encoders convert sound waves into language or acoustic features. Audio encoders identify phonemes, tone patterns, and acoustic signals.
- Language models integrate encoded signals into coherent responses. Language models generate text responses using combined embeddings.
Why do multimodal inputs change the final AI answer? Multimodal inputs change the final AI answer because multimodal signals alter context interpretation and evidence selection. The model selects information that matches signals across modalities. Combined signals often shift the response direction.
What practical tasks rely on multimodal AI input? Multimodal AI input enables several real-world AI capabilities.
There are 5 common multimodal AI tasks. The tasks are listed below.
- Image captioning converts visual scenes into descriptive text. Image captioning explains objects and actions inside images.
- Visual question answering generates answers about image content. Visual question answering connects text questions with image features.
- Speech recognition converts spoken language into text. Speech recognition transforms audio signals into language tokens.
- Video understanding analyzes motion and events across frames. Video analysis detects actions and scene transitions.
- Multimodal search retrieves results from combined image and text queries. Multimodal retrieval matches visual and textual query signals.
Why does multimodal capability vary across AI platforms? Multimodal capability varies across AI platforms because AI platforms train multimodal models with different datasets and architectures. Training data differences affect visual recognition accuracy. Architecture differences affect how signals combine during reasoning.
9. System Prompts and Alignment Policies
Why do system prompts and alignment policies shape an AI answer? System prompts and alignment policies shape an AI answer because system prompts and alignment policies define behavioral rules and response boundaries for the AI system. System prompts refer to hidden instructions embedded inside an AI system that guide how the model behaves. Alignment policies refer to governance rules that restrict unsafe, misleading, or policy-violating responses.
Why do system prompts influence AI responses? System prompts influence AI responses because system prompts define the role, tone, and behavioral framework of the AI assistant. System prompts appear before user prompts during processing. These instructions establish how the AI interprets queries and structures responses.
What instructions exist inside system prompts? System prompts contain structured instructions that guide AI behavior during conversations.
There are 4 main instruction categories inside system prompts. The categories are listed below.
- Role definition specifies the assistant’s identity and expertise. Role instructions define whether the assistant behaves as a researcher, tutor, or conversational guide.
- Behavior rules define acceptable response patterns. Behavior rules instruct the model to provide factual, safe, and relevant answers.
- Output constraints define formatting and explanation style. Output constraints regulate tone, structure, and response clarity.
- Safety policies restrict harmful or misleading responses. Safety policies prevent responses related to dangerous activities or prohibited topics.
Why do alignment policies affect AI answers? Alignment policies affect AI answers because alignment policies enforce safety, ethical, and legal standards during response generation. Alignment policies modify how the model selects and filters outputs. These policies influence refusal behavior, disclaimers, and safety explanations.
What training methods implement alignment policies? There are 3 main training methods that implement alignment policies. The methods are listed below.
- Reinforcement Learning from Human Feedback (RLHF) trains models using human preference signals. Human evaluators rank responses to encourage helpful and safe outputs.
- Supervised fine-tuning of models on curated instruction-response datasets. Instruction datasets teach the model how to follow prompts correctly.
- Policy filtering removes unsafe outputs during generation. Safety filters evaluate generated responses before the final output.
Why do system prompts differ across AI platforms? System prompts differ across AI platforms because each platform defines its own assistant behavior and policy rules. Platform providers configure system prompts with different role definitions, safety boundaries, and response formats.
Why do system prompts change response tone and style? System prompts change response tone and style because system prompts define communication patterns used by the assistant. Tone instructions influence vocabulary, sentence structure, and explanation depth.
What role do alignment policies play in preventing harmful outputs? Alignment policies reduce harmful outputs because alignment policies filter unsafe or misleading responses during generation. These policies detect risk patterns in prompts and responses. Safety filters intervene before the model completes the final output.
Why do system prompts and alignment policies influence AI platform differences?
System prompts and alignment policies influence AI platform differences because system prompts and alignment policies shape behavioral guardrails across AI systems. Different policy frameworks create variation in refusal behavior, answer framing, and allowed content topics.
10. External Knowledge Retrieval (RAG)
Why does external knowledge Retrieval (RAG) shape an AI Answer? External Knowledge Retrieval (RAG) shapes an AI answer because External Knowledge Retrieval (RAG) injects external documents into the response generation process. Retrieval-Augmented Generation (RAG) refers to an architecture that retrieves relevant documents from external knowledge sources before generating an answer. Retrieval-Augmented Generation combines retrieval systems with language models to produce grounded responses.
Why does Retrieval-Augmented Generation influence AI answers? Retrieval-Augmented Generation influences AI answers because Retrieval-Augmented Generation expands the knowledge available during inference. Language models rely on training data stored in model parameters. Retrieval systems supply additional documents that were not part of model training.
What components form a Retrieval-Augmented Generation system? There are 3 main components in a Retrieval-Augmented Generation system. The components are listed below.
- Retriever identifies relevant documents from a knowledge index. The retriever searches vector databases or document indexes for semantically similar content.
- Knowledge source stores structured or unstructured documents. Knowledge sources contain internal databases, documentation repositories, or web content.
- The generator produces the final answer using the retrieved context. The generator integrates retrieved documents into the response generation process.
Why does document retrieval change the final AI answer? Document retrieval changes the final AI answer because retrieved documents alter the context used during generation. Retrieved text appears inside the model context window. The model prioritizes retrieved information during token prediction.
What retrieval methods exist in RAG systems? There are 3 main retrieval methods used in Retrieval-Augmented Generation systems. The methods are listed below.
- Keyword retrieval matches queries with indexed keyword terms. Keyword retrieval uses ranking algorithms that prioritize term frequency and document relevance.
- Vector retrieval matches queries through semantic similarity. Vector retrieval converts queries and documents into embeddings and compares vector distance.
- Hybrid retrieval combines keyword and vector retrieval signals. Hybrid retrieval merges lexical relevance with semantic similarity.
Why does RAG reduce hallucinations in AI responses? Retrieval-Augmented Generation reduces hallucinations because it grounds responses in retrieved source material. Grounded responses reference external documents instead of relying only on model memory.
Why does RAG improve information freshness? Retrieval-Augmented Generation improves information freshness because it retrieves documents from continuously updated sources. Updated knowledge bases supply current information without retraining the model.
What types of knowledge sources power RAG systems? There are 4 main knowledge sources used in Retrieval-Augmented Generation systems. The sources are listed below.
- Internal document repositories store enterprise knowledge. Repositories contain reports, documentation, and internal records.
- Structured databases store structured organizational data. Databases contain tables, product catalogs, and transaction records.
- Web search indexes retrieve publicly available content. Search indexes contain web pages and published documents.
- Vector databases store semantic document embeddings. Vector databases enable similarity search across large document collections.
Why does RAG architecture influence differences across AI platforms? Retrieval-Augmented Generation architecture influences AI platform differences because platforms connect to different retrieval systems and knowledge indexes. Retrieval pipelines vary in indexing methods, document sources, and ranking signals. These differences produce variation in citations, answer framing, and factual coverage across AI platforms.
Why Do AI Platforms Show Different Levels of Freshness?
AI platforms show different levels of freshness because they retrieve and prioritize information through different data access methods and update mechanisms. Freshness refers to how recently the information used in an AI answer was published or updated. Freshness differences appear because AI systems use different retrieval pipelines, indexing strategies, and source evaluation methods.
What factors determine information freshness in AI answers?
There are 5 main factors that determine information freshness in AI answers. The factors are listed below.
1. Real-Time Web Access
2. Source Authority
3. Update Frequency and Refresh Patterns
4. Content Type and Industry
5. Update Schedules
1. Real-Time Web Access
Why is real-time web access the reason why AI platforms show different levels of freshness? Real-time web access shapes AI answer freshness because real-time web access retrieves current information during response generation instead of relying only on training data. Real-time web access refers to the capability of an AI system to query live internet sources while generating an answer. Real-time retrieval introduces recent documents, updated webpages, and live data streams into the model context.
Why does real-time web access change how AI answers are generated? Real-time web access changes AI answers because real-time web access supplies current documents that replace older model knowledge. Language models store patterns learned during training. Live retrieval introduces new evidence that the model prioritizes during token prediction.
What system structure enables real-time web access in AI platforms? Real-time web access operates through dynamic context graphs that assemble information sources during each request. A context graph is a network of connected data sources used by the AI system during reasoning. Context graph nodes contain information sources (account data, APIs, documentation, live system signals).
What properties define context graphs in AI systems? Context graphs contain three defining properties. The properties are listed below.
- A distributed structure connects multiple external systems and services. Context graph nodes exist across APIs, databases, cloud services, and web resources.
- Dynamic composition changes based on user requests. Context graphs assemble different nodes depending on the query context and the user environment.
- Real-time dependency resolution retrieves current information during inference.
Nodes provide information, product documentation, system status, or external knowledge sources.
Why do context graph failures reduce AI answer freshness? Context graph failures reduce AI answer freshness because context graph degradation limits access to live data sources. Context degradation occurs when external dependencies respond slowly or inconsistently. The AI system continues operating, but retrieves incomplete or outdated information.
Why does monitoring context graphs improve AI reliability? Monitoring context graphs improves AI reliability because context monitoring identifies failures in external data dependencies. Observability systems track reachability, latency, and response consistency across nodes. Node-level monitoring identifies which dependency affects context delivery.
Why does real-time web access solve the knowledge cutoff problem? Real-time web access solves the knowledge cutoff problem because real-time retrieval supplements training data with live internet content. Knowledge cutoff refers to the time boundary of model training datasets. Real-time retrieval enables discussion of recent events, software releases, or market updates.
What processing steps occur during real-time web retrieval? There are 5 processing steps in real-time web retrieval. The steps are listed below.
- Query analysis determines whether external retrieval is required. The system analyzes intent, recency signals, and topic volatility.
- Source selection identifies reliable data sources. Retrieval systems rank candidate sources using authority and relevance signals.
- Data retrieval collects documents from live internet sources. The system retrieves articles, documentation, or structured data feeds.
- Context integration merges retrieved data into the model context. Retrieved text enters the prompt context used during generation.
- Response generation produces the final AI answer. The language model generates a response grounded in retrieved information.
Why does real-time web access create differences across AI platforms? Real-time web access creates differences across AI platforms because AI platforms connect to different live data sources and retrieval pipelines. Some platforms rely primarily on training data. Other platforms integrate real-time web retrieval and streaming data systems.
Why does real-time data significantly improve AI decision quality? Real-time data improves AI decision quality because real-time data provides current signals for analysis and prediction. Organizations report measurable improvements when AI systems access live information streams. Real-time systems enable faster decisions, improved personalization, and stronger operational accuracy.
2. Source Authority
Why is source authority the reason why AI platforms show different levels of freshness? Source authority shapes AI answer freshness because source authority determines which documents AI systems trust and retrieve first. Source authority refers to the credibility, expertise, and reliability signals associated with a content source. Source authority develops through consistent publishing quality, citations, backlinks, and recognized expertise.
Why do AI systems prioritize authoritative sources during retrieval? AI systems prioritize authoritative sources because authoritative sources provide historically reliable information signals. AI retrieval systems evaluate credibility signals during document ranking. Universities, research institutes, government organizations, and industry leaders frequently receive higher confidence scores.
Why does source authority influence citation selection in AI answers? Source authority influences citation selection because AI retrieval pipelines score sources based on credibility and structural trust signals. Retrieval systems evaluate domain reputation, entity recognition, and schema consistency. Higher credibility signals increase the probability of document selection during answer generation.
Why does freshness weighting change depending on query type? Freshness weighting changes depending on query type because AI systems evaluate whether recency is required for answer accuracy. Dynamic topics require current information. Stable topics rely on established knowledge that changes slowly.
There are 3 query categories that influence freshness weighting. The categories are listed below.
- Dynamic information queries prioritize freshness as the dominant signal.
Dynamic queries involve news events, regulatory changes, financial markets, and software updates. - Evergreen knowledge queries prioritize authority over recency.
Evergreen topics involve stable concepts, mathematical formulas or foundational principles. - Time-sensitive queries require freshness as a minimum eligibility threshold.
Queries containing explicit time markers (latest, current, 2026) filter out outdated documents.
Why does outdated authoritative content lose visibility over time? Outdated authoritative content loses visibility because it creates a maintenance gap between published content and current reality. The maintenance gap occurs when authoritative sources fail to update content as knowledge evolves. AI systems detect outdated information signals and prioritize updated sources.
Why does freshness alone fail to guarantee visibility in AI answers? Freshness alone fails to guarantee visibility because freshness without authority reaches a citation ceiling. A citation ceiling occurs when newer sources lack credibility signals required for AI citation. Established sources with maintained content often receive higher retrieval priority.
How do AI retrieval systems technically evaluate authority and freshness? AI retrieval systems evaluate authority and freshness through retrieval pipelines that combine semantic similarity and trust scoring. Retrieval-Augmented Generation systems filter candidate documents using vector similarity thresholds. Documents must exceed semantic similarity thresholds before credibility scoring occurs.
Authority scoring includes several structural signals. The signals are listed below.
- Domain reputation signals from citations and backlinks.
Established domains receive higher trust weighting. - Entity consistency signals within knowledge graphs.
Clear entity references increase confidence during document ranking. - Structured data signals from schema markup.
Structured metadata clarifies authorship, organizations, and document structure.
Why do AI platforms display different citation patterns? AI platforms display different citation patterns because they apply different weighting between authority and freshness signals. Some systems emphasize recency signals during retrieval. Other systems emphasize domain authority and knowledge graph trust signals.
Why do authoritative sources remain dominant in competitive topics? Authoritative sources remain dominant because they accumulate credibility signals over long publishing histories. Consistent expertise, citations, and external recognition strengthen authority signals. Strong authority signals increase citation probability in AI-generated answers.
Why does content decay create risk for AI-generated answers? Content decay creates risk because outdated citations reduce factual accuracy and user trust. Many AI systems train on historical datasets with fixed knowledge cutoffs. Outdated information creates misinformation risk in domains with rapid knowledge changes.
Why does structured expertise increase AI citation probability? Structured expertise increases citation probability because structured content signals expertise and trustworthiness to retrieval systems. Structured headings, clear authorship attribution, and schema markup strengthen credibility signals. Strong credibility signals increase the probability of AI citation selection.
3. Update Frequency and Refresh Patterns
Why are update frequency and refresh patterns the reasons why AI platforms show different levels of freshness? Update frequency and refresh patterns shape AI answer freshness because update frequency and refresh patterns determine how fast AI platforms detect, reprocess, and cite changed content. Update frequency refers to how often an AI platform revisits content sources or knowledge systems. Refresh patterns refer to the timing and rhythm used to crawl, index, rank, and reuse updated information.
Why do update frequency and refresh patterns affect AI answer freshness? Update frequency and refresh patterns affect AI answer freshness because AI platforms do not refresh all knowledge layers at the same speed. The foundation model’s knowledge updates slowly. Crawling, indexing, retrieval, and citation layers update faster. These layer differences create visible freshness gaps across AI platforms.
How much fresher is AI-cited content than traditional organic content? AI-cited content is 25.7% fresher than traditional organic Google results. AI platforms prioritize recent and maintained content more aggressively than traditional search systems. This recency bias increases citation probability for pages with substantive updates.
Why do AI platforms detect freshness faster than traditional search systems? AI platforms detect freshness faster because they adjust retrieval and citation systems within days instead of weeks. Retrieval systems process updated content quickly after recrawling and reindexing. Faster adjustment cycles increase the chance that recent documents appear in AI answers.
What signals tell AI platforms that content is genuinely updated? AI platforms detect genuine updates through in-content recency signals and substantive content changes. A changed timestamp alone does not create a strong freshness signal. AI platforms look for new statistics, current year references, recent examples, and meaningful text revisions across the page.
What level of content revision counts as a substantive update? A substantive update changes about 20%-30% of the page content. New sections, new studies, new examples, and revised facts signal meaningful maintenance. Meaningful maintenance increases citation potential across AI systems.
What freshness preferences do major AI platforms show? Major AI platforms show different freshness preferences because each platform uses different retrieval systems, ranking logic, and source weighting. ChatGPT shows the strongest recency bias. Google AI Overviews stay closer to traditional search patterns. Perplexity favors newer and discussion-driven sources. Gemini favors recently published or recently updated content.
What does ChatGPT reveal about AI freshness bias? ChatGPT reveals the strongest freshness bias among major AI platforms. ChatGPT cites URLs that are 393-458 days newer than organic Google results. ChatGPT cites content updated 3 weeks ago at 3.2 times the rate of older content. ChatGPT top cited pages were updated within 30 days in 76.4% of cases.
What does Google AI Overviews reveal about refresh behavior? Google AI Overviews reveal a blended refresh behavior that combines search ranking signals and recency signals. Google AI Overviews cite at least 1 top 10 organic result 93.67% of the time. Roughly 50% of AI Overview citations overlap with Google’s top 10 rankings.
What does Perplexity reveal about freshness and citation order? Perplexity reveals a strong preference for newer and community-validated content. About 50% of Perplexity citations come from 2025 alone in the provided research. Perplexity often orders citations from newest to oldest.
What update layers exist inside AI systems? There are 5 main update layers inside AI systems. The layers are listed below.
- Foundation model updates refresh the slowest. Foundation models update a few times per year. Training cutoffs often lag current events by 6-18 months.
- Web crawling and indexing update faster. High authority pages can be revisited multiple times per day. Low-change pages can wait weeks for reprocessing.
- Retrieval and ranking systems update continuously. Citation behavior can change within days after new documents enter the retrieval system.
- User interaction signals update near real-time. Interaction patterns can boost or suppress answer patterns quickly.
- Curated or enterprise knowledge bases update the fastest. Private knowledge systems can be refreshed in real time or daily.
Why does update cadence matter for AI visibility? Update cadence matters for AI visibility because repeated maintenance increases citation frequency and ranking stability. Systematic refresh frameworks improved citation rates by 292% in the provided material. Content refreshed every 90-120 days, maintained rankings 4.2 positions higher than static content.
What update schedules match different content types? Different content types require different update schedules because different topics change at different speeds. Time-sensitive pages need quarterly updates or immediate revision after new facts appear. Industry analysis benefits from bi-annual refreshes. Evergreen pages need annual reviews or updates every 3-6 months. Product pages need monthly updates for strong ChatGPT visibility.
Which topics face the highest semantic drift risk? Technology, finance, legal, health, ecommerce, and news face the highest semantic drift risk. These topics change quickly through new products, new rules, new prices, and new events. Fast topic change reduces the value of old content even when the source remains authoritative.
Why do brands lose visibility when they ignore refresh patterns? Brands lose visibility when they ignore refresh patterns because stale content drops out of AI citation systems even when it still ranks in traditional search. Traditional search volume is projected to drop by 25% by 2026 in the provided material. AI citation becomes a separate visibility layer that depends heavily on active maintenance.
4. Content and Industry
Why are content and industry the reasons why AI platforms show different levels of freshness? Content and industry shape AI answer freshness because content and industry determine how quickly information becomes outdated. Content type refers to the category of information within a document. Industry refers to the sector where the information applies (technology, finance, healthcare). Different industries change at different speeds, which affects how frequently AI systems prioritize new information.
Why do AI platforms show different freshness preferences? AI platforms show different freshness preferences because they apply different retrieval rules and ranking signals. ChatGPT shows the strongest recency preference among major systems. ChatGPT cites URLs that are 393-458 days newer than organic Google results. ChatGPT top cited pages were updated within 30 days in 76.4% of cases.
Why do Perplexity and Gemini prefer newer content? Perplexity and Gemini prefer newer content because both platforms emphasize current discussion signals and recent publications. About 50% of Perplexity citations come from 2025 in the referenced dataset. Gemini retrieval systems prioritize recently published or recently updated documents.
Why do Google AI Overviews show slightly older citations? Google AI Overviews show slightly older citations because Google AI Overviews integrate traditional search ranking signals with AI retrieval systems. Google AI Overviews cite the top 10 organic results in many cases. Organic ranking stability introduces slightly older but highly authoritative sources.
How does content type determine freshness requirements? Content type determines freshness requirements because different content categories change at different speeds.
There are 3 main freshness categories. The categories are listed below.
- High freshness content requires updates within hours or days. High freshness content includes breaking news, market prices, software releases, and live statistics.
- Medium freshness content requires updates every 6-12 months. Medium freshness content includes product reviews, market analysis, and industry reports.
- Low freshness content requires periodic maintenance reviews. Low freshness content includes historical facts, scientific principles, and foundational educational topics.
Why do some industries require stronger freshness signals? Some industries require stronger freshness signals because the underlying information changes rapidly or carries regulatory risk.
There are 5 industries where freshness signals matter the most. The industries are listed below.
- The technology and artificial intelligence industries change rapidly through product releases and model updates. Frequent updates make older documentation outdated quickly.
- Finance industries require constant updates because market data and regulations change frequently. Outdated financial guidance creates risk and misinformation.
- Legal industries require current regulatory interpretation and case law updates. New legislation changes the validity of older legal explanations.
- Healthcare and wellness industries require alignment with current research and treatment guidelines. Outdated medical advice creates safety and credibility risks.
- E-commerce industries require updates due to price changes, product availability, and market trends. Outdated product information reduces user trust and purchase relevance.
How do AI systems technically evaluate freshness across industries? AI systems evaluate freshness across industries through query intent, semantic relevance, and factual verification. Query intent detection identifies whether the topic requires recent information. Vector embeddings compare terminology against current discourse patterns. Knowledge graph cross-checks validate claims against updated factual sources.
Why does industry speed influence AI citation patterns? Industry speed influences AI citation patterns because fast-evolving industries produce faster semantic drift. Semantic drift occurs when terminology, data, or standards change quickly. AI retrieval systems prioritize newer documents that reflect the latest terminology and facts.
5. Update Schedules
Why are update schedules the reason why AI platforms show different levels of freshness? Update schedules shape AI answer freshness because update schedules determine how frequently AI systems retrain models, recrawl sources, and refresh retrieval indexes. Update schedules refer to the timing cycles used by AI platforms to refresh training data, crawling systems, ranking models, and citation pipelines.
Why do updated schedules influence AI answer freshness? Update schedules influence AI answer freshness because AI platforms refresh different system layers at different intervals. Training data refreshes slowly. Retrieval systems refresh faster. Crawling and indexing systems update continuously.
How much fresher is AI-cited content compared with traditional search results? AI-cited content is 25.7% fresher than traditional Google organic results. AI retrieval systems emphasize recently updated documents more aggressively than traditional search ranking systems.
Why does content freshness strongly influence AI visibility? Content freshness strongly influences AI visibility because AI platforms apply a strong recency bias during citation selection. Content updated three weeks ago receives citations 3.2 times more frequently than older pages. Pages refreshed within 30 days dominate citations across ChatGPT, Perplexity, and Google AI Overviews.
How does AI recency bias affect older content? AI recency bias reduces the visibility of older content because outdated pages fail freshness thresholds during ranking. Many AI systems filter sources older than 3-5 years before applying relevance scoring. Outdated pages lose visibility even if the domain authority remains strong.
What is the content half-life in AI discovery systems? Content half-life in AI discovery systems is approximately 3-6 months for competitive topics. Content half-life refers to the period after which content loses half of its citation visibility. Competitive topics require continuous maintenance to remain visible.
How do AI systems detect real updates instead of superficial edits? AI systems detect real updates through semantic comparison of content versions. AI systems compare newly crawled pages with earlier indexed versions. Superficial changes, modified publish dates without new content, do not increase freshness signals.
What is semantic recency in AI search systems? Semantic recency is the alignment between page content and the current conceptual landscape of a topic. AI retrieval systems generate vector embeddings for indexed documents. Updated content generates new embeddings that match current terminology and knowledge patterns.
What update frequencies maintain AI citation visibility? There are 4 main update frequencies that maintain AI citation visibility. The frequencies are listed below.
- Quarterly updates maintain visibility for time-sensitive pages. Product comparisons, regulatory guides, and compliance content require updates every 3 months.
- Bi-annual updates maintain visibility for industry analysis content. Market reports and technology trend analysis require updates every 6 months.
- Annual reviews maintain evergreen educational content. Foundational knowledge pages require yearly updates to address semantic drift.
- Immediate updates maintain breaking news or event-driven content.
News and fast-evolving events require updates within hours or days.
Why do some industries require more aggressive update schedules? Some industries require aggressive update schedules because terminology, regulations, and data change rapidly. Technology, finance, law, healthcare, and e-commerce experience rapid information change cycles.
What role does training data lag play in freshness differences across AI platforms? Training data lag influences freshness because most AI models train on data collected 6-18 months earlier. Model training cycles introduce delays between real-world events and model knowledge.
What knowledge cutoff differences exist across AI platforms? AI platforms use different training cutoffs that influence baseline knowledge freshness. ChatGPT models released in 2026 reference training data through August 2025. Gemini models referenced training data through January 2025. Retrieval-based systems extend knowledge through live search integration.
How often do AI platforms update their models? AI platforms update models across several cycles.
There are 3 common update cycles. The cycles are listed below.
- Major architectural upgrades occur every 1-2 years. These releases introduce new model architectures or major capability changes.
- Intermediate model updates occur several times per year. These releases incorporate new training datasets and improvements.
- System-level updates occur weekly or continuously. Providers adjust safety rules, ranking logic, and infrastructure regularly.
Why do updated schedules create long delays in AI knowledge updates? Update schedules create delays because retraining large models requires massive computational resources and long processing cycles. Full retraining of frontier models can require months of compute time and massive infrastructure.
How Personalization and Context Change AI Results?
Personalization and context affect AI results because they modify the signals AI systems use to interpret intent, rank information, and generate responses. Personalization refers to adapting results based on user behavior, preferences, and historical interactions. Context refers to dynamic signals surrounding a query (location, device, timing, conversation history, emotional tone, or stage in a task).
Why does personalization change AI answers? Personalization changes AI answers because personalization modifies ranking signals based on individual user data. Personalization systems analyze behavioral signals (purchase history, browsing activity, prior searches). These signals alter the ranking of results and the generation of responses.
Why do businesses prioritize AI personalization systems? Businesses prioritize AI personalization because personalization increases revenue, conversion rates, and marketing efficiency. Targeted promotions influence purchase behavior for 65% of customers. AI-driven personalization reduces customer acquisition costs by up to 50%. AI-driven personalization increases revenue between 5% and 15%.
Why do consumers expect personalized experiences? Consumers expect personalized experiences because personalized interactions increase relevance and reduce friction in decision-making. 71% of consumers expect personalized interactions during digital experiences. 76% of consumers experience frustration when personalization does not occur.
Why did early personalization systems fail to deliver strong results? Early personalization systems failed because they relied on static rule-based segmentation instead of contextual learning. Rule-based systems grouped customers into fixed segments. These systems ignored real-time behavioral signals and changing user intent.
How does generative AI improve personalization capabilities? Generative AI improves personalization because generative AI models analyze intent, context, and language patterns in real time. Large Language Models process conversational input and behavioral signals simultaneously. Real-time generation enables dynamic responses, personalized recommendations, and adaptive messaging.
What contextual signals influence AI personalization results? There are 5 main contextual signals that influence AI personalization results. The signals are listed below.
- User behavior history influences recommendations and ranking decisions. Browsing history, purchases, and prior interactions shape future results.
- Conversation context influences answer framing and follow-up responses. AI systems interpret prior messages to maintain logical continuity.
- Location signals influence geographically relevant information. Geo-location data adjusts recommendations, offers, and local search results.
- Purchase stage signals influence recommendations and messaging tone. Early research queries produce informational answers. Late-stage queries emphasize product comparisons and purchase guidance.
- Emotional or sentiment signals influence tone and response style. AI chatbots analyze sentiment to respond with empathy or urgency.
Why does context influence AI-generated answers more than static search systems? Context influences AI answers more strongly because AI systems process multi-turn conversations and dynamic behavioral signals. Traditional search engines rely primarily on keywords and page ranking signals. AI systems interpret user intent through conversation history and semantic signals.
What strategic components enable effective AI personalization systems? There are 5 core components that enable effective AI personalization systems. The components are listed below.
- Unified data architecture integrates customer data across channels.
Unified data layers create a single customer view for personalization. - Decision engines rank offers and content based on predictive models.
Predictive models estimate promotion success and engagement probability. - Content generation systems create tailored content variations.
Generative AI tools produce personalized text, images, and campaign assets. - Real-time distribution systems deliver personalized content across channels.
Messaging systems synchronize web, email, and mobile experiences. - Measurement frameworks evaluate personalization performance continuously.
Performance metrics track conversion rates, engagement, and customer lifetime value.
Why does context determine recommendation accuracy in AI systems? Context determines recommendation accuracy because context clarifies the user’s problem that the AI must solve. AI systems analyze query phrasing, recent behavior, and situational signals. These signals reduce ambiguity and increase recommendation precision.
What industries benefit most from AI personalization systems? AI personalization systems benefit multiple industries through tailored experiences and automated decision support.
There are 4 industries where personalization produces strong results. The industries are listed below.
- E-commerce uses AI personalization for product recommendations and dynamic pricing. Personalized search and recommendations increase purchase probability.
- Healthcare uses AI personalization for patient monitoring and treatment guidance. AI systems analyze patient data to support personalized care.
- Education uses AI personalization for adaptive learning platforms. Adaptive systems adjust learning content based on student performance.
- Hospitality uses AI personalization for customer engagement and experience optimization. Hotels personalize recommendations, reservations, and travel experiences.
Why do personalization and context increase AI trust and engagement? Personalization and context increase AI trust and engagement because relevant responses align with user intent and situational needs. Personalized experiences increase customer satisfaction and engagement. Consumers choose or recommend brands offering personalized experiences in 77% of cases.
How to Compare AI Platforms Fairly?
Comparing AI platforms fairly requires structured evaluation metrics, controlled testing methodology, defined selection factors, and bias prevention. AI platform comparison refers to the systematic evaluation of multiple AI systems using standardized criteria and repeatable testing conditions. Fair comparison requires identical prompts, consistent evaluation metrics, and controlled experimental design.
What steps ensure fair AI platform comparison? There are 4 main steps that ensure fair AI platform comparison. The steps are listed below.
1. Define Evaluation Metrics
2. Choose the Right Methodology
3. Include Key Selection Factors
4. Avoid Bias in Evaluation
1. Define Evaluation Metrics
Why is it important to define evaluation metrics to compare AI platforms fairly? Defining evaluation metrics is important to compare AI platforms fairly because evaluation metrics establish objective standards for measuring AI performance and reliability. Evaluation metrics refer to quantitative indicators used to assess how well an AI system performs across accuracy, relevance, safety, and user experience. Evaluation metrics create a shared measurement framework that allows consistent comparison across platforms.
Why do AI systems require specialized evaluation metrics? AI systems require specialized evaluation metrics because AI systems generate probabilistic outputs rather than deterministic results. Probabilistic outputs mean responses vary across repeated queries. Evaluation metrics measure patterns of performance instead of single correct outputs.
How do AI evaluation metrics differ from traditional IT system measurements? AI evaluation metrics differ from traditional IT measurements because AI evaluation focuses on trust, reasoning quality, and safety in addition to technical performance.
| Feature / Aspect | AI Evaluation Metrics | Traditional IT System Measurements |
|---|---|---|
| Core Purpose | Evaluate AI effectiveness, trustworthiness, and business value in probabilistic systems. | Measure deterministic system performance and reliability. |
| Scope of Measurement | Includes safety, fairness, reasoning quality, and user experience signals. | Focuses on speed, availability, and functional correctness. |
| Key Challenges Addressed | Handles uncertainty, dynamic environments, and risk of harmful outputs. | Handles predictable behavior and static input-output systems. |
| Metric Examples | Bias ratio, explainability index, guardrail compliance, helpfulness, and factual error rate. | Accuracy, precision, recall, error rate, latency, uptime. |
| Output Quality Focus | Measures clarity, relevance, truthfulness, and response consistency. | Measures binary correctness and system specification compliance. |
| Development Impact | Guides model optimization and detects regressions in model behavior. | Validates infrastructure stability and operational health. |
| Business Value | Quantifies ROI, decision quality, and user trust in AI products. | Ensures operational efficiency and SLA compliance. |
| Trust and Safety | Evaluates ethical behavior and policy alignment in generated outputs. | Assumes correct system behavior with minimal ethical evaluation. |
Why do evaluation metrics improve trust in AI systems? Evaluation metrics improve trust in AI systems because they expose weaknesses and unintended behaviors before deployment. Structured evaluation reveals accuracy gaps, bias patterns, and hallucination risks. Early detection prevents unreliable responses from reaching users.
Why do evaluation metrics matter in high-risk AI applications? Evaluation metrics matter in high-risk AI applications because they enforce quality thresholds required for safe decision-making. Domains (medicine, finance, and law) require strict output reliability. Evaluation metrics define acceptable performance levels for these environments.
Why do evaluation metrics accelerate AI development cycles? Evaluation metrics accelerate AI development cycles because they create measurable baselines for improvement. Baseline measurements allow teams to detect regressions after model updates. Faster testing enables rapid iteration and safe model upgrades.
What problems appear when AI systems lack evaluation metrics? AI systems without evaluation metrics produce unreliable outputs because teams cannot detect quality failures systematically. Ad hoc testing fails to capture subtle biases or reasoning errors. Lack of evaluation metrics leads to unpredictable system behavior in production.
2. Choose the Right Methodology
Why is it important to choose the right methodology to compare AI platforms fairly? Choosing the right methodology is important to compare AI platforms fairly because methodology determines whether evaluation results reflect real-world performance. Evaluation methodology refers to the structured testing process used to measure AI systems across consistent datasets, prompts, and evaluation criteria. Correct methodology reduces deployment risk and ensures results represent real-world behavior.
Why does methodology affect AI platform comparison results? Methodology affects AI platform comparison results because testing design controls dataset selection, prompt structure, and evaluation conditions. Controlled testing conditions produce comparable results across platforms. Poor testing design produces misleading performance measurements.
How does fair methodology differ from improper comparison methods? Fair methodology differs from improper comparison methods because fair methodology uses standardized testing conditions and deployment-relevant datasets.
| Feature / Aspect | Fair Comparison Methodology | Improper Comparison Methodology |
|---|---|---|
| Risk Mitigation | Reduces deployment risk through real-world performance validation. | Increases deployment risk through misleading benchmark results. |
| Decision Making | Supports evidence-based resource allocation and strategic planning. | Produces suboptimal decisions and failed product launches. |
| Validation of Performance | Uses objective benchmarks aligned with real-world tasks. | Uses benchmarks disconnected from production environments. |
| Context and Compliance | Evaluates ethical, operational, and regulatory requirements. | Ignores privacy, legal, and compliance risks. |
| Evaluation Criteria | Applies task-specific metrics aligned with deployment goals. | Uses generic datasets unrelated to real-world use cases. |
| Testing Conditions | Uses identical datasets, prompts, and evaluation interfaces. | Test platforms using inconsistent datasets or prompts. |
| Data Strategy | Uses evaluation datasets that mirror production environments. | Uses training datasets reused for evaluation tasks. |
| Ethical Considerations | Includes safety, privacy, and fairness assessments. | Overlooks ethical and regulatory risks. |
Why does fair methodology reduce AI deployment risk? Fair methodology reduces AI deployment risk because fair methodology tests models under realistic operating conditions. Real-world simulation reveals weaknesses that controlled laboratory tests often hide. Early detection prevents failures during production deployment.
Why does methodology influence strategic decision-making? Methodology influences strategic decision-making because methodology determines which performance signals guide investment choices. Reliable evaluation results direct resources toward the most effective AI platform. Misleading benchmarks cause investment in unsuitable models.
Why must evaluation datasets match deployment environments? Evaluation datasets must match deployment environments because a dataset mismatch creates unrealistic performance measurements. Generic benchmark datasets rarely reflect real operational conditions. Deployment-aligned datasets reveal practical performance strengths and limitations.
Why do standardized testing conditions matter in AI evaluation? Standardized testing conditions matter because standardized testing conditions eliminate experimental bias during comparison. Using identical prompts, datasets, and testing interfaces ensures that differences in results originate from model capability rather than testing variation.
What risks appear when organizations use improper evaluation methodology? Improper evaluation methodology creates several risks that reduce AI project success.
There are 4 main risks. The risks are listed below.
- Deployment failure occurs when models perform well in testing but fail in production.
Controlled benchmarks often miss real-world complexity. - Resource misallocation occurs when misleading metrics guide investment decisions.
Teams invest in models optimized for irrelevant benchmarks. - Compliance failures occur when ethical and regulatory risks are ignored.
An incomplete evaluation fails to detect privacy or safety risks. - User trust declines when deployed models deliver unreliable results.
Poor real-world performance damages product credibility.
Why does rigorous methodology improve long-term AI ROI? Rigorous methodology improves long-term ROI because rigorous evaluation prevents costly deployment failures and rework. A structured evaluation process identifies unsuitable models early. Early detection reduces operational costs and increases project success probability.
3. Include Key Selection Factors
Why is it important to include key selection factors to compare AI platforms fairly? Including key selection factors is important to compare AI platforms fairly because key selection factors connect platform evaluation to business goals, operating needs, and deployment risk. Key selection factors refer to the criteria that determine whether an AI platform fits the required use case, technical environment, governance standard, and growth plan. Key selection factors turn platform comparison from a feature checklist into a decision framework.
Why do key selection factors matter more than feature lists? Key selection factors matter more than feature lists because feature lists describe capability, while selection factors define fit. A platform with many features can still fail in production. Fit depends on goals, workflows, integration, security, and long-term viability.
Why does strategic alignment matter in AI platform comparison? Strategic alignment matters because it ensures the AI platform addresses a defined business objective. Clear objectives narrow the platform shortlist. Clear objectives improve return on investment because the platform is chosen for a measurable outcome.
Why does operational efficiency matter in platform selection? Operational efficiency matters because operational efficiency determines whether the platform performs reliably at an organizational scale. Scalability, deployment flexibility, and workload handling shape long-term platform value. Weak scalability creates migration risk and rising infrastructure costs.
Why does user adoption matter in AI platform evaluation? User adoption matters because user adoption determines whether the platform creates value after purchase. Intuitive interfaces, training resources, and smooth onboarding reduce resistance. Better adoption increases productivity and shortens time to value.
Why does system integration matter in AI platform selection? System integration matters because it determines whether the platform can use the right data at the right time. Platforms that connect with enterprise systems reduce fragmentation. Strong integration improves data consistency across customer, product, and operational workflows.
Why do risk and trust need to appear in the selection process? Risk and trust need to appear in the selection process because AI platforms handle sensitive data, automated decisions, and compliance exposure. Security controls, audit logs, explainability, and governance features reduce legal and reputational risk. Trust features matter most in regulated and high-impact environments.
Why does financial evaluation belong in platform comparison? Financial evaluation belongs in platform comparison because platform value depends on total cost and measurable return. License cost alone does not show the true platform cost. Maintenance, support, training, scaling, and upgrade needs shape the total cost of ownership.
Why do vendor reliability and support matter? Vendor reliability and support matter because they affect platform stability, onboarding success, and issue resolution speed. Strong support reduces downtime and implementation friction. Reliable vendors strengthen long-term platform performance through updates and technical guidance.
Why does future-proofing matter in AI platform comparison? Future-proofing matters because it protects the organization from platform obsolescence. AI technology changes quickly. Platforms with regular updates, customization options, and flexible model strategies remain useful longer.
Why do ethical considerations and transparency need to be selection factors? Ethical considerations and transparency need to be selection factors because they reduce bias, legal risk, and harmful outputs. Transparent systems make decisions easier to review. Strong governance controls improve accountability and public trust.
Why do key selection factors improve fair comparison? Key selection factors improve fair comparison because key selection factors force every platform to be judged against the same real decision criteria. Consistent criteria reduce demo bias. Consistent criteria increase the chance that the selected platform performs well after deployment.
4. Avoid Bias in Evaluation
Why is it important to avoid bias in evaluation to compare AI platforms fairly? Avoiding bias in evaluation is important to compare AI platforms fairly because bias distorts results, hides weaknesses, and leads to unsafe platform choices. Evaluation bias refers to any testing condition, dataset choice, scoring method, or reviewer judgment that unfairly favors one platform over another. Bias in evaluation weakens trust because the final ranking no longer reflects true platform performance.
Why does biased evaluation damage AI platform comparison? Biased evaluation damages AI platform comparison because biased evaluation produces misleading performance signals. Misleading signals create false confidence in weak systems. False confidence leads to poor deployment decisions, wasted budget, and avoidable failures.
How does an unbiased evaluation differ from a biased evaluation? Unbiased evaluation differs from biased evaluation because unbiased evaluation applies balanced data, consistent conditions, and fair scoring rules.
| Feature / Aspect | Biased AI Platform Evaluation | Unbiased AI Platform Evaluation |
|---|---|---|
| Trust and Acceptance | Eroses trust and reduces confidence in results. | Builds trust in platform comparison and final decisions. |
| Legal and Ethical Impact | Increases discrimination and compliance risk. | Reduces discrimination and strengthens ethical review. |
| Operational Consistency | Hides subgroup failures and uneven performance. | Reveals stable performance across different groups. |
| Organizational Reputation | Creates reputation damage after deployment failures. | Protects reputation through fair and defensible selection. |
| Harm Prevention | Misses harmful patterns in outputs or decisions. | Detects harmful patterns before deployment. |
| Bias Handling | Uses weak audits or narrow checks. | Uses structured bias review across the full evaluation process. |
| Regulatory Readiness | Increases exposure to legal action and fines. | Improves compliance readiness and documentation. |
| Model Reliability | Creates silent failures for certain cases or groups. | Improves reliability across realistic scenarios. |
Why does evaluation bias create legal and ethical risk? Evaluation bias creates legal and ethical risk because biased testing can approve systems that discriminate or fail unevenly across groups. Hidden bias in hiring, lending, healthcare, and customer service creates direct harm. Direct harm creates legal exposure and public trust loss.
Why does evaluation bias weaken operational reliability? Evaluation bias weakens operational reliability because evaluation bias masks subgroup errors and edge-case failures. A platform can show strong average performance while failing on critical segments. Average scores alone do not reveal equitable performance.
Why does unbiased evaluation improve trust in AI platform selection? Unbiased evaluation improves trust because unbiased evaluation produces defensible evidence for platform choice. Stakeholders trust decisions when testing conditions are consistent and transparent. Transparent evidence strengthens adoption and governance.
What practices reduce bias in AI platform evaluation? There are 6 main practices that reduce bias in AI platform evaluation. The practices are listed below.
- Use balanced datasets across demographic groups, task types, and difficulty levels. Balanced datasets reduce skewed platform advantage.
- Use identical prompts, settings, and scoring rules for every platform. Standardized conditions improve comparability.
- Test subgroup performance, not just average performance. Subgroup testing exposes silent failure patterns.
- Include human review for fairness, tone, and harmful output detection. Human review captures issues that raw metrics miss.
- Audit results across the full lifecycle from data selection to final reporting. Lifecycle auditing detects bias early and late in the process.
- Document methodology, limitations, and decision logic clearly. Clear documentation improves accountability and repeatability.
Why is a biased evaluation method never a sound choice? A biased evaluation method is never a sound choice because short-term speed gains create long-term legal, financial, and operational costs. Skipping fairness checks reduces initial effort. That reduced effort increases the chance of harmful deployment, rework, fines, and reputation damage.
Why does avoiding bias improve fair platform comparison? Avoiding bias improves fair platform comparison because avoiding bias makes the comparison reflect actual capability instead of testing distortion. Fair testing protects the organization and the affected audience. Fair testing leads to stronger platform selection, stronger trust, and stronger long-term performance.
How Do AI Hallucinations Influence Platform Differences?
AI hallucinations influence platform differences because AI hallucinations change factual accuracy, citation reliability, response style, and trust across AI platforms. AI hallucinations refer to plausible but false outputs generated by artificial intelligence systems during next-token prediction. AI hallucinations create visible platform differences because each platform uses different training data, retrieval layers, safety rules, reasoning methods, and response policies.
What are AI hallucinations in practical terms? AI hallucinations are fabricated, incorrect, or unverifiable outputs that an AI model presents as valid information. AI hallucinations appear as fake facts, fake quotes, fake citations, fake legal cases, or false numerical claims. AI hallucinations matter because confident falsehoods reduce trust and create legal, financial, and operational risk.
Why do AI hallucinations differ across AI platforms? AI hallucinations differ across AI platforms because AI platforms use different architectures, datasets, retrieval systems, and policy layers. Some platforms rely more heavily on model memory. Some platforms rely more heavily on live retrieval or Retrieval-Augmented Generation (RAG). These design differences change how often the model guesses, grounds answers, or refuses uncertain claims.
What structural cause creates hallucinations in all LLM platforms? Probabilistic next-token prediction creates hallucinations in all LLM platforms because probabilistic next-token prediction selects likely language, not guaranteed truth. Large Language Models (LLMs) generate the next token from statistical patterns in training data. This mechanism produces fluent language. This mechanism does not guarantee factual correctness.
What real examples show platform differences in hallucination behavior? Real examples show that AI hallucinations appear across all major platforms, but the form and impact differ by platform. ChatGPT produced fake quotes, fake legal cases, fake financial figures, and false accusations in documented cases. Google Bard made a false James Webb Space Telescope claim during a public demo. Google AI Overviews returned absurd advice from weak source interpretation. Meta Galactica cited fictitious research and was withdrawn after public failure. These cases show that platform differences change the error pattern, not the existence of hallucination risk.
How do retrieval systems change hallucination differences between platforms? Retrieval systems change hallucination differences between platforms because retrieval systems inject external documents into answer generation. Retrieval-Augmented Generation grounds answers in retrieved sources. Grounded retrieval reduces unsupported claims. Grounded retrieval does not remove hallucinations completely because the model can still misread, overstate, or ignore retrieved evidence.
Why do hallucinations affect trust differently across platforms? Hallucinations affect trust differently across platforms because platforms differ in confidence style, citation behavior, and source visibility. A platform that cites sources clearly gives the reader a way to inspect the claim. A platform that hides sourcing creates a harder verification task. Trust depends on both error rate and error visibility.
Can hallucinations be eliminated across AI platforms today? No, hallucinations cannot be eliminated fully across AI platforms today because hallucinations are a structural limitation of probabilistic generation models. Current models generate language from probability, not direct truth checking. Platforms can reduce hallucination frequency. Platforms cannot remove hallucination risk completely with the current model design.
What platform difference matters most when hallucinations are compared? The most important platform difference is not whether hallucinations exist, but how each platform constrains, reveals, and manages hallucinations. One platform hallucinates less through retrieval grounding. Another platform exposes citations better. Another platform refuses uncertain prompts more often. These management differences shape real-world reliability more than raw fluency alone.
What Are the Risks of AI Platform Variability?
AI platform variability creates risks because different AI platforms produce inconsistent outputs, behaviors, and decision patterns for the same input. AI platform variability refers to differences in model architecture, training data, retrieval systems, alignment policies, and evaluation methods across platforms. These differences create variability in accuracy, safety, reliability, and governance outcomes.
What risks emerge from AI platform variability? There are 10 main risks associated with AI platform variability. The risks are listed below.
1. Expanding Attack Surface (Security Risk)
2. Data Privacy Risks (Privacy Risk)
3. Intellectual Property Risks (Legal Risk)
4. Misleading or Incorrect Results (Accuracy Risk)
5. Biased Results (Fairness Risk)
6. Dynamic and Evolving Nature of AI (Operational Risk)
7. Black-Box Algorithms and Transparency Issues (Transparency Risk)
8. AI-Specific Vulnerabilities (Security Risk)
9. New Cybersecurity Risks (Security Risk)
10. Inadequacy of Traditional Frameworks (Framework Risk)
What Are the Limitations of AI Visibility Measurement?
AI visibility measurement has limitations because AI systems generate dynamic, private, and probabilistic outputs that cannot be fully tracked or indexed. AI visibility measurement refers to the process of estimating how often a brand, product, or entity appears in AI-generated answers. Measurement limitations exist because AI responses change continuously, platforms restrict access to usage data, and outputs are not publicly indexed.
Why does dynamic answer generation limit AI visibility measurement? Dynamic answer generation limits AI visibility measurement because AI systems produce different answers for the same prompt across sessions. AI responses change based on conversation history, user location, and contextual signals. This variability prevents stable tracking of consistent results.
Why does probabilistic generation reduce measurement accuracy? Probabilistic generation reduces measurement accuracy because LLM outputs are generated from likelihood predictions rather than fixed results. Traditional search engines return deterministic rankings. AI systems generate answers dynamically, which prevents stable baseline visibility measurement.
Why do hallucinations reduce reliability in visibility tracking?
Hallucinations reduce reliability in visibility tracking because AI systems can generate false citations or invented sources. A hallucinated citation appears as a brand mention even when no real source exists. This behavior introduces noise into measurement datasets.
Why does the lack of a crawlable index restrict large-scale analysis? The lack of a crawlable index restricts large-scale analysis because AI responses are not stored in public indexes. Crawlers cannot scan AI responses the way they scan websites. Automated monitoring becomes impossible at scale.
Why do API limitations restrict AI visibility monitoring? API limitations restrict AI visibility monitoring because AI APIs only generate answers for submitted prompts. APIs do not expose answers generated for other users. Monitoring systems observe only test queries rather than real outputs.
Why is brand mention tracking fundamentally incomplete in AI systems?
Brand mention tracking is fundamentally incomplete because even AI platform providers cannot fully measure their own output mentions. Responses occur privately across millions of interactions. Internal analytics systems cannot reconstruct every generated answer.
Why is averaging visibility across AI platforms unreliable?
Averaging visibility across AI platforms is unreliable because each AI platform retrieves information from different data sources and ranking logic. Each platform produces different citation patterns. Visibility analysis must evaluate platforms individually instead of averaging results.
Can Strong SEO Rankings Guarantee AI Mentions?
No, strong SEO rankings cannot guarantee AI mentions because AI systems select sources using different retrieval, synthesis, and citation rules than traditional search engines. Strong SEO rankings refer to high positions in search engine result pages based on ranking signals, backlinks, authority, and content relevance. AI mentions refer to brand or source citations inside AI-generated answers.
Why do strong SEO rankings not guarantee AI mentions? Strong SEO rankings do not guarantee AI mentions because AI systems synthesize answers instead of listing ranked links. Traditional search engines display ranked webpages. AI systems generate summarized answers and include only a small set of supporting sources.
Why does AI discovery prioritize inclusion rather than ranking? AI discovery prioritizes inclusion because AI answers display only a limited number of cited sources inside generated responses. AI-generated answers often resolve the question directly without requiring a click. This pattern shifts visibility from rank position to citation presence.
Why can strong SEO rankings still influence AI mentions? Strong SEO rankings still influence AI mentions because AI retrieval systems frequently draw from authoritative and well-ranked sources. Google AI Overviews often cite pages that already rank in the top 10 organic search results. Strong authority signals increase the probability of inclusion.
Why does strong SEO remain important even without guaranteed AI mentions?
Strong SEO remains important because strong SEO provides the foundational signals used by AI retrieval systems. High-quality content, authority signals, and entity consistency increase the probability of appearing in AI-generated answers.
Do AI Platforms Prefer Concise Answers Over Long-Form Content?
Yes, AI platforms prefer concise answers because concise answers resolve user intent quickly and fit the structure of AI-generated summaries. Concise answers refer to short, factual explanations that appear at the beginning of a document. AI-generated summaries extract information that directly answers the user’s question.
Why do AI platforms prioritize concise answers? AI platforms prioritize concise answers because concise answers provide a direct resolution to the user’s question. AI models often extract information from the first sentences of a document. Content that answers the question immediately increases the probability of citation.
Why do short summaries increase AI citation probability? Short summaries increase AI citation probability because structured summaries simplify information extraction. Paragraph-length summaries placed at the beginning of content show 35% higher inclusion in AI-generated snippets. Clear summaries improve machine readability and answer relevance.
Why do users prefer concise AI-generated responses? Users prefer concise responses because concise responses reduce browsing effort and decision time. A 2025 survey reported that 68% of users prefer a single AI-curated answer instead of browsing multiple webpages.
Why does long-form content still matter for complex topics? Long-form content still matters because complex topics require deeper explanation and supporting evidence. Financial, health, and legal topics involve high-stakes decisions. These topics require detailed reasoning and transparent sourcing.
Why does long-form research increase AI visibility? Long-form research increases AI visibility because original data and expert analysis strengthen authority signals. Proprietary insights and original reporting increase the probability of AI citation even when the final answer shown to users is concise.
Will AI Visibility Become More Important Than Organic Rankings?
Yes, AI visibility will become more important than organic rankings because AI-generated answers increasingly influence discovery and decision-making before users visit websites. AI visibility refers to how often a brand, product, or source appears inside AI-generated answers. Organic rankings refer to a webpage’s position within traditional search engine results pages.
Why does AI visibility influence user decisions earlier than organic rankings? AI visibility influences decisions earlier because AI assistants deliver summarized answers that resolve questions without requiring clicks. AI-generated summaries often provide recommendations, comparisons, and brand mentions directly in the response. Nearly 60% of Google searches ended without a click in 2024 due to AI summaries.
Why do AI citations receive more engagement than traditional search links? AI citations receive more engagement because AI-generated answers present a curated set of sources instead of a long ranked list. Users frequently select links referenced inside the AI answer. Studies show visitors arriving from LLM platforms convert at approximately 8× the rate of traditional search traffic.
Why do organic rankings still influence AI visibility? Organic rankings still influence AI visibility because AI systems frequently retrieve information from high-ranking search results. Approximately 94% of AI Overview answers cite at least one source from the top 20 organic results. Strong search performance increases the probability of an AI citation.
Why does AI visibility not fully replace organic rankings?
AI visibility does not fully replace organic rankings because AI systems still rely on search indexes as their underlying content sources. Strong SEO signals increase content credibility, authority, and retrieval probability within AI systems.
Should Brands Optimize Separately for Each AI Platform?
Yes, brands should optimize separately for each AI platform because each AI platform uses different training data, retrieval systems, and citation logic. Platform-specific optimization refers to adapting the content strategy for each AI ecosystem. Different AI systems surface different brands for the same query.
Why do AI platforms show different brand recommendations? AI platforms show different brand recommendations because each platform retrieves information from different data sources and ranking models. Google AI Overviews rely heavily on Google’s search index. Perplexity relies on the Brave search index and real-time retrieval. ChatGPT blends training data with retrieval systems.
Why do platform differences create visibility gaps? Platform differences create visibility gaps because identical queries produce different brand mentions across platforms. Research shows Google AI Overviews and ChatGPT recommend different brands in 61.9% of identical
Will AI Platforms Eventually Show Identical Results?
No, AI platforms will not show identical results because large language models generate outputs probabilistically and optimize for different objectives. Identical results would require deterministic generation and identical training processes across platforms. Current AI systems intentionally include variability.
Why do LLMs produce different answers for the same prompt? LLMs produce different answers because LLMs predict tokens from probability distributions rather than fixed rule systems. Multiple tokens often have similar probabilities. The model selects among these possibilities during generation.
Why do training differences create output variation across platforms? Training differences create output variation because models train on different datasets and optimization objectives. One model prioritizes factual precision. Another model prioritizes conversational fluency or creativity.
Why do internal settings create output variability? Internal settings create output variability because inference parameters influence token selection behavior. Temperature controls randomness during generation. Higher temperatures produce more diverse outputs.
Why does infrastructure affect AI output consistency? Infrastructure affects AI output consistency because server load and batch processing influence inference calculation order. This phenomenon is called batch variance. Small numerical differences during computation can change the final token selection.
Why will platform differences likely persist in the future? Platform differences will likely persist because AI developers optimize models for different product goals and user experiences. Some systems emphasize speed. Others emphasize reasoning accuracy or creativity. These design choices will continue producing distinct outputs across platforms.





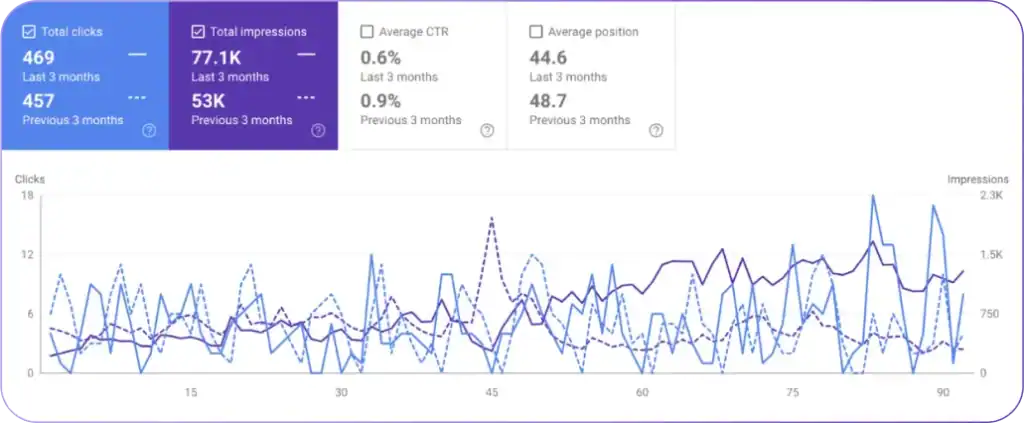
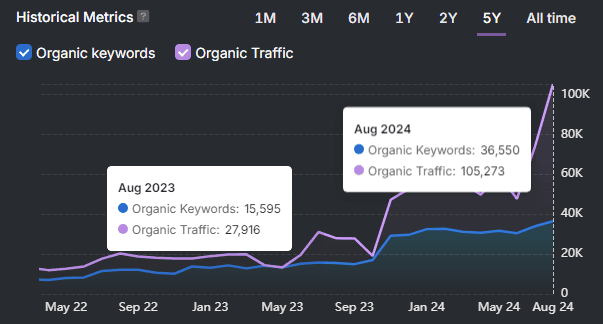
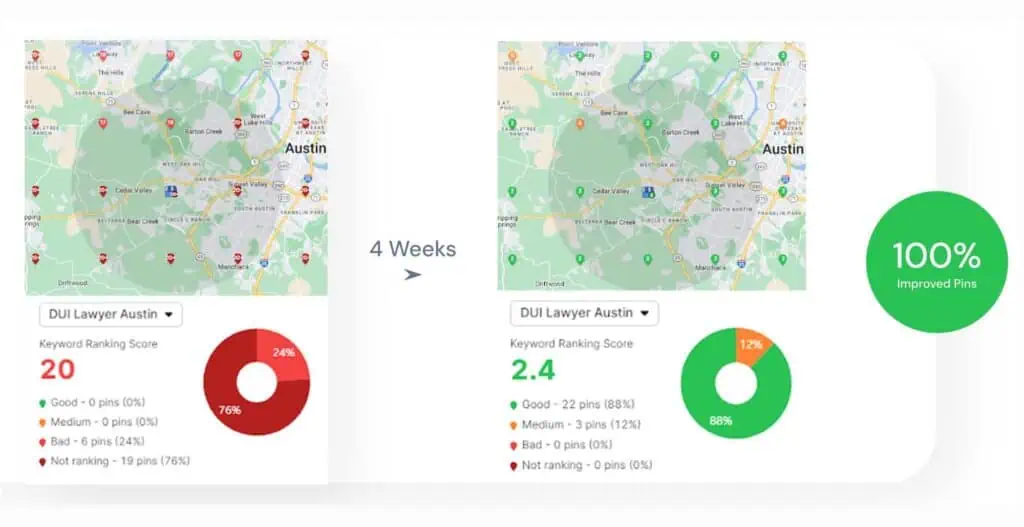
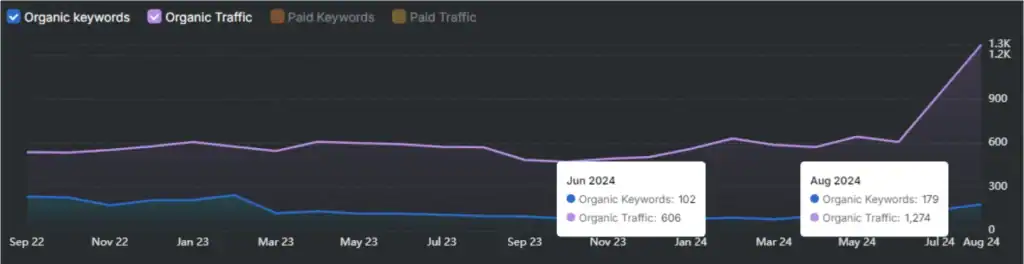
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}