

Large Language Models (LLMs) interpret content through statistical signals, structural hierarchy, and contextual weighting rather than factual verification. This interpretation explains how LLMs select, prioritize, and generate answers from competing information sources. LLM interpretation matters because output quality depends on how clearly signals, structure, and context align within the input.
LLMs prioritize completion over uncertainty, which leads to single, confident answers even when conflicting information exists. Most generations resolve into one definitive response, with averages near 80% across models and higher rates above 90% in optimized systems. Refusal behavior remains rare, which shows that LLMs favor answering over expressing uncertainty. This pattern explains why outputs appear decisive even when underlying data conflicts.
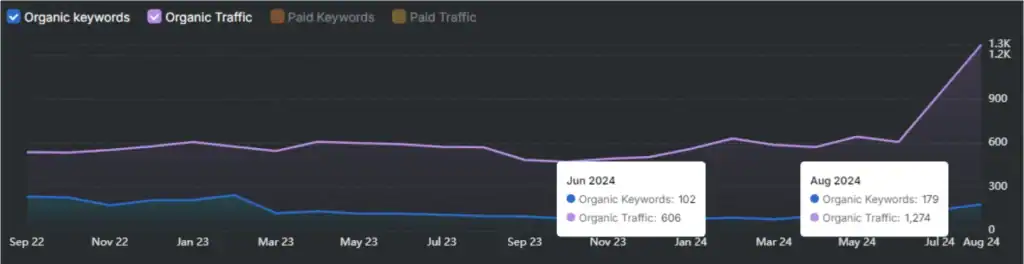
Signal strength influences selection through repetition and positional weighting. Repetition increases perceived importance, where repeated statements gain a higher probability of selection regardless of accuracy. Position introduces bias where later information often overrides earlier inputs, especially in structured sequences. These signals show that LLMs weigh prominence rather than evaluating all inputs equally, which affects how product descriptions and claims are interpreted.
Structure determines how effectively LLMs segment and extract meaning from content. Clear hierarchy, defined sections, and consistent formatting improve how models interpret relationships between ideas. Weak structure introduces ambiguity, which reduces extraction accuracy and increases the risk of misinterpretation. Structured content creates predictable interpretation paths, while unstructured content creates fragmented understanding.
Context defines how LLMs connect information across sentences, sections, and concepts. LLMs detect conflicts with high precision at a surface level but struggle to resolve those conflicts during generation. Models often blend incompatible details into a single narrative or select one dominant answer without acknowledging alternatives. This behavior results from statistical completion rather than logical validation.
LLM interpretation improves when signals, structure, and context remain consistent across the entire content set. Retrieval-Augmented Generation systems increase reliability by introducing verified sources and prioritizing consistent information. Clear formatting, aligned messaging, and repeated factual consistency reduce ambiguity and improve output stability. This alignment explains why well-structured, context-rich content produces more accurate and reusable AI-generated answers.
What Are Large Language Models (LLMs)?
Large language models (LLMs) are an advanced subcategory of artificial intelligence that understand and generate human language and other content, characterized by deep learning models trained on immense amounts of data and built on transformer neural network architectures. LLMs represent a major leap in human-technology interaction as the first AI systems capable of handling unstructured human language at scale, which allows natural communication with machines.
When did large language models emerge, and what enabled their growth? The development of LLMs is the culmination of decades of progress in natural language processing (NLP) and machine learning research, largely responsible for the explosion of AI advancements in the late 2010s and 2020s. The transformer architecture, crucial for modern LLMs, was introduced in 2017 by Vaswani et al. in “Attention Is All You Need.” OpenAI developed the first GPT series in 2018, with GPT-3 (2020) cementing LLMs as a transformative force with 175 billion parameters.
As generative AI models, LLMs belong to the broader class of foundation models and are built upon deep learning, neural networks, and machine learning. LLMs are distinguished from traditional search engines by capturing deeper context, nuance, and reasoning, rather than relying on keyword matching. They differ from earlier recurrent neural networks (RNNs) by evaluating the whole context simultaneously, rather than processing information “token by token.”
How LLMs Work?
Large Language Models (LLMs) work by predicting the next token in a sequence based on patterns learned from massive text corpora. LLMs use deep learning, transformer architectures, and probabilistic decoding to generate language that appears coherent, relevant, and context-aware. This process makes LLMs powerful for writing, summarization, question answering, and conversation, but the underlying mechanism remains statistical prediction rather than human-style understanding or awareness.
Predictive Probability and Next-Token Generation
Predictive probability and next-token generation define how LLMs produce text through conditional probability modeling. The model calculates the likelihood of every possible next token given the current context, then selects one token based on a decoding strategy. This process repeats in an autoregressive loop, which allows the model to construct sentences step by step while maintaining local coherence.
How does next-token generation influence output quality? Next-token generation influences output quality because each token depends on the accumulated context, which allows the model to maintain topic continuity and stylistic consistency. Strong probability alignment produces fluent and relevant text, while weak alignment introduces repetition, drift, or incorrect continuations.
How do decoding strategies affect generation? Decoding strategies affect generation by controlling how deterministic or diverse the output becomes. Greedy decoding produces stable but repetitive text, while sampling methods introduce variation by selecting from a range of likely tokens. This balance between probability and variation defines whether output feels rigid or natural.
Training on Patterns
Training on patterns explains how LLMs learn language structure, relationships, and usage from large datasets. The model adjusts internal parameters during training to improve prediction accuracy across billions of examples. This process captures statistical regularities in grammar, phrasing, and semantic relationships without encoding explicit rules.
Why is pattern learning central to LLM behavior? Pattern learning is central because the model relies entirely on learned distributions to generate output. The model identifies recurring structures in text and uses those structures to predict future tokens. This mechanism allows LLMs to imitate tone, answer questions, and generate structured content across domains.
What limitations emerge from pattern-based learning? Pattern-based learning introduces limitations because statistical prediction does not guarantee factual correctness. The model generates outputs that appear plausible based on learned patterns, even when information conflicts or lacks grounding. This limitation explains hallucinations, overgeneralization, and confident errors.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation improves how LLMs work by injecting external knowledge into the generation process. RAG systems retrieve relevant information from external sources and include that information in the model input context before generation begins. This approach grounds responses in real data instead of relying only on training patterns.
What is the purpose of Retrieval-Augmented Generation? The purpose of RAG is to improve accuracy, relevance, and trust by connecting LLM outputs to external knowledge sources. RAG extends model capability beyond its training data, which addresses knowledge gaps, outdated information, and domain-specific limitations.
How does RAG improve response quality? RAG improves response quality by supplying context that aligns directly with the user query. Retrieved information reduces unsupported assumptions and increases factual grounding. This process produces more reliable and useful outputs in scenarios that require precision, current data, or proprietary knowledge.
What challenges affect RAG performance? RAG performance depends on retrieval quality, context selection, and system design. Irrelevant or low-quality retrieval reduces answer accuracy, while token limits restrict how much context the model uses. Effective RAG requires strong retrieval pipelines, a clean data structure, and precise ranking to ensure the most relevant information enters the generation step.
What Is Content for LLMs?
Content for LLMs is a structured information format that is designed to be accurately interpreted, reused, and cited by LLMs (ChatGPT, Claude, or Gemini), characterized by an additional layer of precision and structure for machine-level comprehension beyond traditional human-focused SEO.
Content for LLMs refers to content structured in a way that allows AI systems to extract precise answers, understand context, and reuse information without ambiguity. Content for LLMs aligns structure, wording, and formatting with how LLMs retrieve and synthesize information. This approach ensures that content becomes part of the answer layer inside AI systems rather than remaining as a standalone page.
What does content for LLMs optimize? Content for LLMs optimizes structure, clarity, and answer precision so AI systems extract and reuse information reliably. Content for LLMs optimizes question-based headings, direct answers, semantic chunking, and contextual completeness. These attributes determine whether a content block qualifies for extraction and citation inside AI-generated responses.
What are the key attributes of content for LLMs? Content for LLMs depends on structural clarity, factual density, and E-E-A-T signals to qualify for extraction and citation. Structural clarity defines how content is organized through headings, hierarchy, and segmentation, which allows models to identify answer boundaries. Factual density defines how much verifiable information exists per section, which increases trust and reduces ambiguity. E-E-A-T signals define credibility through experience, expertise, authority, and trust, which influence whether a model selects a source for citation.
What does content for LLMs enable? Content for LLMs enables inclusion inside AI-generated answers, higher citation rates, and improved visibility across AI search systems. Content for LLMs enables AI Overviews, conversational search responses, and internal knowledge retrieval systems. These outcomes increase exposure without relying on clicks, which shifts performance measurement from traffic to answer presence.
How LLM Interpretation Differs from Traditional Search Engines?
LLM interpretation and traditional search engines perform different roles in how information is discovered, processed, and presented. LLMs operate as answer engines that synthesize and generate responses, while traditional search engines operate as retrieval systems that rank and display links. This distinction shifts visibility from ranked placement on a results page to inclusion inside a generated answer.
What are the core functional differences between LLMs and traditional search engines? LLMs generate direct answers, summaries, and comparisons by synthesizing information into a single response. This process reduces the need for users to click external links, which creates zero-click behavior. Traditional search engines retrieve indexed pages and present ranked lists of links based on relevance signals. This model requires users to select and visit pages to access information. LLMs aim to resolve the query within the response itself, while search engines aim to guide users toward external sources.
What technological differences define LLM interpretation and traditional search? LLMs interpret content by breaking text into tokens and analyzing relationships through attention mechanisms that evaluate the full context simultaneously. This process focuses on semantic clarity, coherence, and answer completeness. Traditional search engines rely on crawling, indexing, and ranking systems that evaluate pages using metadata, links, and structured signals. Modern search engines incorporate embeddings and semantic ranking, but the core system still prioritizes document retrieval rather than answer synthesis.
What differences exist in how content is presented and optimized? LLMs present content as a direct, structured answer that prioritizes clarity, factual density, and completeness. Content optimized for LLMs focuses on answering questions directly, maintaining clear structure, and reducing ambiguity. Traditional search engines present content as ranked links, where optimization focuses on ranking signals, click-through rates, and competitive positioning. Content in traditional search varies in structure because ranking depends on signals beyond.
Why Understanding LLM Interpretation Matters?
Understanding LLM interpretation matters because AI systems now influence decisions, recommendations, and knowledge across critical domains where errors carry real consequences. LLM interpretation defines how outputs are evaluated, trusted, and acted upon in environments where AI-generated answers guide behavior. This shift makes interpretation essential for distinguishing between fluent responses and reliable reasoning.
What is the core importance of LLM interpretation? LLM interpretation improves trust, transparency, and accountability by revealing how models generate outputs from given inputs. Interpretation allows teams to trace which signals influenced a response, which enables better judgment about output quality. This capability becomes critical in high-impact scenarios where AI-generated recommendations affect financial, medical, or operational decisions. Interpretation transforms LLM usage from blind acceptance into controlled evaluation.
What benefits does LLM interpretation provide for systems and organizations? LLM interpretation enables faster debugging, stronger governance, and more stable system performance. Interpretation identifies failure points by isolating patterns, prompts, or data segments that lead to incorrect outputs. This visibility allows teams to correct issues directly and improve system reliability. Interpretation creates audit trails that support compliance, risk management, and regulatory requirements. These audit trails document how outputs were generated, which strengthens accountability across AI deployments.
What challenges exist in understanding LLM interpretation? LLM interpretation faces limitations because models do not expose explicit reasoning processes in a transparent or consistent way. Outputs emerge from probabilistic pattern matching, which makes internal decision pathways difficult to trace precisely. Generated explanations from the model itself do not guarantee accuracy because the explanation is another generated output, not a verified reasoning trace. This limitation creates a gap between what the model says and why the model produced that output. Automated interpretation systems are required to scale analysis across millions of interactions, since manual inspection cannot keep pace with model complexity.
What are the implications for LLM “understanding”? LLM interpretation clarifies that fluent language generation does not equal human-like understanding. Models simulate reasoning through pattern completion, not through conscious comprehension or awareness. This distinction matters because users often project intent, intelligence, or judgment onto systems that operate purely on statistical prediction. Interpretation reduces this misconception by grounding evaluation in observable behavior rather than perceived intelligence. This clarity improves how users interact with AI systems and reduces overreliance on outputs that appear authoritative but lack verified grounding.
What is the future relevance of LLM interpretation? LLM interpretation becomes more critical as AI systems expand across content creation, decision support, and automated workflows. Interpretation enables better control over how AI systems generate summaries, recommendations, and explanations at scale. As AI becomes embedded in everyday processes, interpretation determines whether outputs remain reliable, safe, and aligned with intended use. This role positions interpretation as a foundational layer for managing AI systems, ensuring that performance, trust, and accountability remain consistent as adoption grows.
8 Key Signals LLMs Use To Interpret Content
LLMs interpret content through structural, semantic, and contextual signals that shape how information is understood, extracted, and reused inside generated answers. These signals determine whether a page is clear enough to parse, coherent enough to trust, and specific enough to cite. Strong signal alignment improves extraction accuracy, reduces ambiguity, and increases the likelihood that AI systems select a source for summarization or citation.
The 8 key signals LLMs use to interpret content are listed below.
1. Heading hierarchy and order. LLMs use heading hierarchy and order to understand topic boundaries, concept importance, and the relationship between main ideas and supporting details. A clear H1, H2, and H3 structure gives models a map of the page, which improves chunking, retrieval, and summarization. Pages with logical heading order are easier for LLMs to segment into reusable answer blocks, while skipped or disordered headings weaken relationship signals between sections. This signal matters because AI systems often process content in semantically grouped units, and headings define where those units begin, end, and connect.
2. Context and concept relationships. LLMs interpret meaning through context and concept relationships rather than isolated word matching. Models analyze how terms connect across sentences, paragraphs, and sections, which allows them to infer topical relevance, semantic alignment, and conceptual depth. This signal matters because AI systems favor content that explains how ideas relate, not just content that repeats keywords. Pages that connect entities, definitions, examples, and supporting concepts in a coherent sequence are easier for LLMs to interpret as authoritative and complete.
3. Entities over isolated keywords. LLMs prioritize entities because entities represent real concepts, people, brands, products, places, and topics that exist within larger semantic networks. Models analyze how entities appear, how consistently they are described, and how clearly they connect to adjacent concepts. This signal matters because modern AI systems evaluate topical meaning through entity relationships, not keyword density. Pages that define entities clearly, maintain naming consistency, and reinforce connections across related content give LLMs stronger signals about what the page is about and why it matters.
4. Formatting lists, tables, and FAQs. LLMs use formatting cues to identify extractable information blocks that are quoted, summarized, or repurposed inside answers. Lists make sequence and hierarchy easier to parse. Tables make comparisons easier to retrieve. FAQ sections align directly with the question-answer structure that many AI systems are trained to reuse. This signal matters because content formatting reduces friction during extraction. Content that presents comparisons, steps, attributes, and definitions in clean visual structures is more likely to be selected than dense prose that hides key information.
5. Paragraph focus and clarity. LLMs interpret paragraphs as compact meaning units, which makes paragraph focus and clarity essential for reliable extraction. Paragraphs that stay on one idea, lead with the main claim, and support that claim with direct explanation are easier for models to summarize accurately. Paragraphs that drift across multiple ideas or delay the point weaken interpretability and increase retrieval errors. This signal matters because a single paragraph often becomes the exact passage an AI system uses to represent a source. Focused paragraphs improve summarization, reduce hallucination risk, and strengthen answer quality.
6. Semantic patterns and redundancy signals. LLMs detect semantic patterns and redundancy signals to judge whether information is distinct, repetitive, or overly similar to adjacent content. Strong semantic variation across sections improves informational coverage, while excessive repetition makes content appear generic or low value. This signal matters because AI systems prefer information that adds new meaning rather than repeating the same phrasing in slightly different forms. Pages that reinforce key concepts without duplicating language excessively create better retrieval quality and stronger interpretive precision.
7. Supportive authority signals. LLMs evaluate supportive authority signals to estimate whether a source is credible, experienced, and safe to reuse. These signals include expert authorship, brand consistency, citations, external references, proprietary data, clear sourcing, and trust-oriented presentation. Authority does not come from one signal alone. Authority comes from consistent reinforcement across the page, the domain, and the broader web. This signal matters because AI systems prefer content that reduces uncertainty. Pages that combine clear expertise, transparent sourcing, and corroborated claims are more likely to be used in generated responses.
8. Internal linking and topical clustering. LLMs use internal linking and topical clustering to understand how pages relate within a broader subject area. Internal links create semantic pathways that connect pillar pages, subtopics, definitions, and supporting resources. These connections strengthen topic depth, clarify entity relationships, and signal that a site covers a subject comprehensively rather than superficially. This signal matters because AI systems interpret well-linked topic clusters as evidence of organized expertise. Strong internal linking improves contextual understanding, strengthens retrieval quality, and increases the probability that related pages are treated as part of one authoritative knowledge system
What Are the Differences Between Structured and Unstructured Content?
Structured content and unstructured content differ in how information is organized, stored, and interpreted by systems. Structured content follows a defined schema that makes information easier to classify, query, and reuse. Unstructured content does not follow a fixed model, which makes information richer in context but harder for machines to process directly. This distinction matters because machine readability, searchability, and extraction quality depend heavily on content structure.
What is structured content? Structured content refers to information organized within predefined fields, attributes, and relationships. Structured content usually appears in formats that follow clear patterns, which makes the content easy for systems to parse consistently. Structured content is content organized through a predefined model that tells a system exactly what each element represents. This model creates predictable formatting across records, pages, or data objects. Structured content improves machine readability because the system does not need to guess where a title, date, product name, or attribute begins and ends. Structured content improves consistency, searchability, and reuse across applications, databases, and AI systems.
What is unstructured content? Unstructured content refers to information that exists in free-form formats without a rigid schema. Unstructured content often contains valuable context and nuance, but that value is harder to access without additional interpretation layers. Unstructured content is content that exists without a fixed schema or consistent field-level organization. This content appears in formats such as free-form text, documents, images, video, and audio, where meaning exists inside the content itself rather than inside predefined labels. Unstructured content carries richer narrative detail, descriptive context, and expressive variation, but systems need additional processing to identify what the content means and how its parts relate.
Why is structured content easier for machines to process? Structured content is easier for machines to process because each element exists inside a known format with explicit boundaries and roles. Systems identify fields, compare values, and retrieve attributes with high accuracy. This structure reduces ambiguity and improves extraction, filtering, and transformation. Structured content, therefore, performs strongly in environments where precision, retrieval speed, and repeatable interpretation matter most.
Why is unstructured content harder to process but often richer in meaning? Unstructured content is harder to process because systems need to infer meaning from free-form language, visual signals, or mixed media instead of reading predefined labels. This inference requires natural language processing, computer vision, or other advanced interpretation methods. Unstructured content often carries richer meaning because it preserves explanation, nuance, tone, and contextual depth that rigid schemas cannot capture easily. This richness makes unstructured content valuable for understanding intent, emotion, and complex concepts.
What are the main operational differences between structured and unstructured content? Structured content is typically stored in relational databases, data warehouses, or other systems built around fixed fields and schema control. Unstructured content is typically stored in object storage, data lakes, document repositories, or systems designed to hold many file types without schema enforcement. Structured content is easier to query directly, while unstructured content usually requires preprocessing, extraction, or model-based interpretation before analysis becomes reliable.
How do structured and unstructured content differ in flexibility? Structured content offers lower flexibility because schema changes require planning, coordination, and system updates. Unstructured content offers higher flexibility because it accommodates almost any format or content type without redesigning the storage model first. This difference creates a tradeoff between efficiency and adaptability. Structured content improves consistency and reuse, while unstructured content preserves breadth, detail, and expressive range.
Why does this difference matter for AI and search systems? This difference matters because AI systems interpret structured and unstructured content in different ways. Structured content gives AI cleaner signals, clearer entities, and easier extraction paths. Unstructured content gives AI deeper context, broader examples, and richer descriptive material, but only after interpretation layers convert that material into usable meaning. Strong content systems often combine both forms by using structure to improve retrieval and using unstructured detail to improve depth and contextual relevance.
Why Is Structured Content Important for LLMs?
Structured content is important for LLMs because it improves accuracy, reduces ambiguity, and increases the reliability of generated answers. LLMs rely on patterns from input data, which means poor structure leads directly to poor outputs. Clean structure creates clear meaning boundaries, which improves how models interpret, retrieve, and reuse information.
Why do LLMs depend on structured input for accuracy? LLMs depend on structured input because models learn from patterns, not from verified knowledge. Structured content reduces noise, enforces consistency, and defines relationships between elements. This structure lowers error rates and improves answer precision because the model receives clearer signals about what each piece of information represents.
How does structured content reduce hallucinations and errors? Structured content reduces hallucinations and errors because it removes ambiguity from the input data. Clear headings, defined sections, and labeled attributes prevent models from guessing meaning. This clarity improves factual alignment and reduces the risk of incorrect or fabricated outputs during generation.
Why does structured content improve consistency across outputs? Structured content improves consistency because it standardizes how information appears across inputs. Consistent formatting produces consistent patterns, which stabilizes model behavior. This stability ensures that similar queries return similar, reliable answers instead of unpredictable variations.
How To Structure Content For AI Search?

Structuring content for AI search requires organizing information in a way that AI systems easily identify, extract, and reuse inside generated answers. AI search platforms do not evaluate pages only as full documents. AI search platforms break pages into smaller sections, interpret those sections independently, and select the clearest blocks for summaries, citations, and direct answers. This shift makes structure a primary visibility factor because strong structure improves machine readability, citation accuracy, and answer inclusion.
The 7 methods to structure content for AI search are listed below.
- Use clear headings and subheadings
- Keep answers short and direct
- Use lists, steps, and tables
- Use FAQs to address common queries
- Highlight key takeaways
- Maintain topical authority
- Implement schema markup
1. Use Clear Headings and Subheadings
Clear headings and subheadings improve AI search performance because headings define topic boundaries and tell AI systems what each section covers. AI systems process content in chunks rather than as one uninterrupted page, which means headings function as semantic anchors that separate definitions, comparisons, steps, and explanations into distinct units. A clear H1, H2, and H3 hierarchy improves chunking accuracy, reduces confusion between main ideas and supporting details, and increases the chance that a section gets selected for an AI-generated answer. Headings framed as natural questions perform especially well because they mirror the way users phrase prompts in ChatGPT, Perplexity, Google AI Overviews, and other answer engines. Specific headings like “What Is Retrieval-Augmented Generation?” or “How Does Schema Markup Improve AI Visibility?” give stronger interpretation signals than vague headings like “More Information” or “Learn More.” Strong heading structure therefore improves discoverability, strengthens machine interpretation, and increases the likelihood that a page is cited accurately.
2. Keep Answers Short and Direct
Short and direct answers improve AI search visibility because AI systems prefer content that resolves intent immediately. AI models scan pages to find the clearest answer block first, then expand into supporting detail only when needed. A section that begins with a concise answer is much easier for AI systems to extract than a section that delays the point behind a long setup, vague context, or filler language. This behavior explains why featured snippets, AI Overviews, and zero-click answers often pull from short sections that state the answer in the first sentence. Direct answers reduce ambiguity, improve confidence in extraction, and make the content easier to summarize across different search contexts. Clear, short answers improve user experience as well because they reduce friction and make long-form content easier to scan. AI-friendly writing does not mean shallow writing. AI-friendly writing means frontloading the main answer, then expanding with examples, proof, and nuance. This structure makes content more useful for both answer engines and human readers.
3. Use Lists, Steps, and Tables
Lists, steps, and tables improve AI search performance because they convert information into formats that AI systems parse quickly and reuse with minimal reconstruction. AI models look for content blocks that already contain logical separation between ideas, and structured formats provide that separation clearly. Lists work well for key points, steps, features, pros and cons, and comparisons because each item becomes a discrete extraction unit. Ordered steps work especially well for procedural queries because AI systems preserve the sequence during summarization. Tables work well for pricing, features, dimensions, comparisons, and side-by-side evaluation because headers define attributes and cells define values. This structure reduces interpretation effort and increases citation accuracy. Well-structured content blocks are easier for AI systems to transform into answer cards, summaries, quick comparisons, and snippet-style outputs. Structured formats improve user readability at the same time because they reduce visual density and make information easier to absorb. Lists, steps, and tables therefore improve both machine extraction and human comprehension, which makes them one of the strongest formatting signals in AI search.
4. Use FAQs to Address Common Queries
FAQs improve AI search visibility because question-and-answer formatting closely matches how users interact with answer engines. AI systems are designed to process natural-language questions, so content that already mirrors that structure becomes easier to extract, validate, and reuse. A strong FAQ section turns a page into a set of ready-made answer blocks that surface across many long-tail and conversational queries. This structure works particularly well for voice search, zero-click search, and AI-generated summaries because each answer stands on its own without requiring much surrounding context. FAQ sections improve coverage by addressing specific objections, use cases, comparisons, and clarifications that do not fit naturally into the main body copy. FAQ formatting is especially effective when each answer starts with a direct sentence, stays concise, and expands only as needed. When paired with the FAQ schema, this structure becomes even easier for AI systems to interpret. FAQs therefore increase search relevance, improve answer eligibility, and expand the number of ways a page surfaces inside AI-generated results.
5. Highlight Key Takeaways
Key takeaways improve AI search performance because they condense the most important insights into highly extractable summary blocks. AI systems favor sections that reduce ambiguity and state the main conclusion clearly, which makes takeaway sections useful for both summarization and citation. A strong takeaway block gives AI a concise representation of page value, topic relevance, and practical outcome. This matters because AI search engines often need a high-confidence summary before deciding whether a source deserves inclusion. Key takeaways strengthen this decision by surfacing the core message early and clearly. They improve human usability in the same way because they make long-form pages easier to scan and easier to understand. Summary sections at the top of a page, under major headings, or at the end of major sections give both AI systems and readers a compressed version of the most important information. This structure improves interpretability, reduces the risk of misrepresentation, and increases the likelihood that the page contributes directly to generated answers.
6. Maintain Topical Authority
Topical authority improves AI search visibility because AI systems prefer sources that demonstrate depth, consistency, and expertise across an entire subject area. AI search does not evaluate a page only by isolated keywords. AI search evaluates whether a site repeatedly covers related concepts, answers adjacent questions, and builds a coherent body of knowledge around a topic. Pages from sites with strong topical authority are safer sources for AI systems because they reduce the risk of inaccurate or incomplete answers. This preference explains why comprehensive hubs, topic clusters, and internally connected content ecosystems often outperform isolated articles. Topical authority strengthens trust because it shows that the source understands the broader context, not just a single term. It improves retrieval because AI systems connect related pages into a larger semantic network. Topical authority increases citation likelihood, strengthens entity recognition, and improves the probability that a brand appears consistently across AI-generated answers.
7. Implement Schema Markup
Schema markup improves AI search visibility because it gives machines explicit clues about what a page contains, what each entity represents, and how page elements relate to one another. AI systems do not rely only on raw text. AI systems use structured signals to confirm meaning, reduce ambiguity, and interpret content with greater confidence. Schema acts as a translation layer between page content and machine understanding by labeling products, FAQs, reviews, organizations, articles, authors, and other entities in a standardized format. This structure increases eligibility for rich results and strengthens the page’s usefulness in AI-generated summaries. Schema does not replace strong content structure, but schema strengthens it by making meaning easier to verify. Pages with well-implemented schemas are easier to classify, easier to parse, and easier to trust. This improvement matters in AI search because answer engines prefer sources that are both readable and machine-interpretable. Schema markup supports better content understanding, stronger extraction accuracy, and higher visibility across AI-powered search experiences.
How Schema Boosts AI Visibility?
Schema boosts AI visibility by structuring content into explicit, machine-readable signals that AI systems interpret, verify, and reuse. Schema improves visibility because AI systems rely on clear entity definitions, relationships, and content types to select sources for generated answers.
Schema markup refers to a structured data framework that labels page elements using a standardized vocabulary. Schema markup defines entities, attributes, and relationships in a format that AI systems process without ambiguity.
How does schema markup improve AI visibility? Schema markup improves AI visibility by clarifying entity meaning, content purpose, and contextual relationships. Schema markup aligns page data with how AI systems retrieve and synthesize information. These mechanisms define how schema increases inclusion, citation, and reuse inside AI-generated answers.
Why Context-Driven Content Outperforms Keyword-Heavy Pages?
Context-driven content outperforms keyword-heavy pages because AI systems prioritize meaning, intent, and real-world application over keyword repetition. Context-driven content improves visibility because AI systems match answers to user intent rather than exact keyword phrases. This shift matters because modern search evaluates how well content solves a specific problem, not how often it repeats a term.
Context-driven content refers to content structured around a specific use case, audience, problem, or comparison scenario. Context-driven content connects a topic to a real situation, which improves relevance and answer accuracy.
How does context-driven content improve AI search performance? Context-driven content improves AI search performance by aligning directly with user intent and query meaning. Context-driven content gives AI systems clear signals about what problem the content solves and who it targets. These signals increase extraction accuracy, improve answer relevance, and raise citation probability inside AI-generated results.
What Are Common Mistakes When Writing Content for LLMs?
The common mistakes when writing content for LLMs are structural inconsistency, weak linguistic clarity, and poor data quality. These mistakes reduce how accurately LLMs interpret, extract, and reuse information. These mistakes matter because LLMs rely on patterns, structure, and input quality rather than true understanding.
The 3 common mistakes when writing content for LLMs are listed below.
- Structural and formatting errors. Structural mistakes reduce clarity and break how LLMs segment and interpret content.
- Linguistic and content strategy mistakes. Linguistic issues distort meaning and reduce interpretation accuracy.
- Technical and data-related mistakes. Poor data quality leads to unreliable outputs and hallucinations.
1. Structural and Formatting Errors. Structural and formatting errors reduce LLM performance because an unclear structure weakens how models segment and interpret content. LLMs process text in chunks, which means that missing hierarchy, inconsistent formatting, or mixed topics create confusion during extraction. Poor structure prevents models from identifying where one idea ends and another begins, which lowers accuracy and reduces citation reliability. Content without clear headings, logical flow, or defined sections becomes harder for LLMs to interpret correctly. Strong structure improves clarity, while weak structure introduces ambiguity that leads to incorrect outputs.
2. Linguistic and Content Strategy Mistakes. Linguistic and content strategy mistakes reduce LLM accuracy because unclear language distorts meaning and weakens interpretation signals. LLMs depend on precise phrasing to map intent, which means spelling errors, grammar issues, or vague wording change how a prompt or content is understood. These issues lead to incorrect outputs, inconsistent structure, or failure to follow instructions. Linguistic inconsistencies even create unexpected behavior because models associate patterns with meaning instead of reasoning about intent. Clear, consistent language improves reliability, while poor phrasing increases unpredictability and reduces output quality.
3. Technical and Data-Related Mistakes. Technical and data-related mistakes reduce LLM reliability because models reflect the quality of the data they process. LLMs trained or grounded on noisy, outdated, or inconsistent data produce equally unreliable outputs. Poor data introduces hallucinations, incorrect associations, and misleading answers because LLMs do not validate truth. Models generate responses based on probability, not factual verification, which means errors in data propagate into outputs. Clean, structured, and validated data improves performance, while messy data increases error rates and reduces trust in generated content.
What Are the Risks and Limitations of LLM Content Interpretation?
The risks and limitations of LLM content interpretation include hallucinations, weak contextual memory, limited reasoning depth, and bias in outputs. These limitations affect how reliably LLMs interpret, summarize, and generate content. These limitations matter because LLMs predict patterns rather than verify facts or maintain a true understanding.
What causes hallucinations and accuracy issues in LLM interpretation? Hallucinations occur because LLMs generate responses based on probability instead of factual retrieval. LLMs produce confident but incorrect answers when data is missing, unclear, or inconsistent. This behavior reduces trust and creates risk in high-stakes contexts like healthcare, finance, and legal decisions.
Why do LLMs struggle with context and memory? LLMs struggle with context because models process inputs within limited context windows and do not retain persistent memory across interactions. This limitation leads to fragmented understanding in long conversations and weak performance in multi-step tasks that require continuity.
Why do reasoning and problem-solving remain limited in LLMs? Reasoning remains limited because LLMs simulate logic through pattern recognition instead of true step-by-step understanding. LLMs fail on complex problems, produce inconsistent answers, and break reasoning chains when tasks require deeper logical consistency.
How do bias and data quality affect LLM outputs? Bias and data quality affect outputs because LLMs learn directly from training data patterns. Biased, outdated, or incomplete data produces biased and unreliable responses. These issues reinforce inequalities and reduce fairness across different users and contexts.
Why do privacy and security risks exist in LLM systems? Privacy and security risks exist because LLMs process large volumes of data that contain sensitive information. Improper handling or exposure leads to leakage of personal or confidential data, which creates compliance and security concerns.
Why does overreliance on LLMs create additional risks? Overreliance creates risks because users accept generated answers without verification. This behavior reduces critical thinking and increases the chance of acting on incorrect or misleading information generated by the model.
Do LLMs Understand Content the Same Way Humans Do?
No, large language models (LLMs) do not understand content the same way humans do because LLMs rely on statistical prediction instead of cognitive understanding. Human understanding depends on reasoning, experience, and contextual awareness, while LLM interpretation depends on patterns learned from large datasets. This difference defines how each system processes meaning, context, and knowledge.
LLMs generate language by predicting the next token based on probability, which creates fluent responses without true comprehension. Humans interpret meaning through intent, context, and lived experience, which allows flexible reasoning across new situations. LLMs require massive datasets to approximate language patterns, while humans learn efficiently from limited exposure through abstraction and analogy.
Can Strong SEO Rankings Guarantee LLM Inclusion?
No, strong traditional SEO rankings do not guarantee inclusion in LLM answers because LLMs prioritize extractability, clarity, and authority over ranking position. A page ranking first in search results remains absent from AI-generated answers, while a lower-ranked page is selected if it explains a topic more clearly. This behavior shifts visibility from ranking position to content usability inside AI systems.
Traditional SEO remains foundational because most LLM systems rely on retrieval layers that access indexed content before generating answers. Strong SEO ensures content is discoverable, while structured formatting and clear explanations determine whether that content is selected and cited. This relationship shows that SEO enables access, while LLM optimization determines inclusion.
How Do LLMs Handle Conflicting Information?
LLMs handle conflicting information by selecting a single dominant answer rather than presenting multiple perspectives. LLMs favor coherence and confidence, which leads to one response even when multiple valid answers exist. This behavior occurs because models optimize for the most probable continuation instead of evaluating truth across competing sources.
LLMs show a strong bias toward single-answer outputs, with most generations producing one confident response and very few expressing uncertainty. This tendency reduces ambiguity but increases the risk of incorrect conclusions when input data conflicts. Repetition, position, and phrasing influence which answer is selected, which demonstrates that LLM decisions depend on patterns rather than verification.






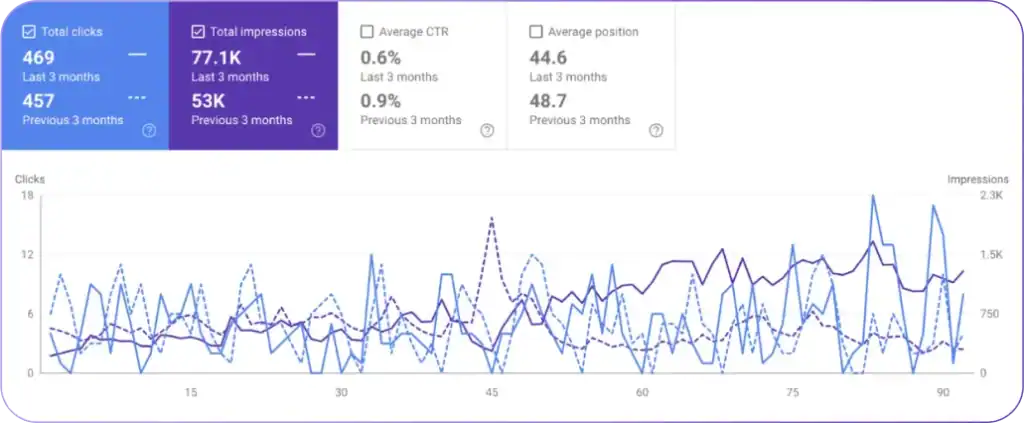
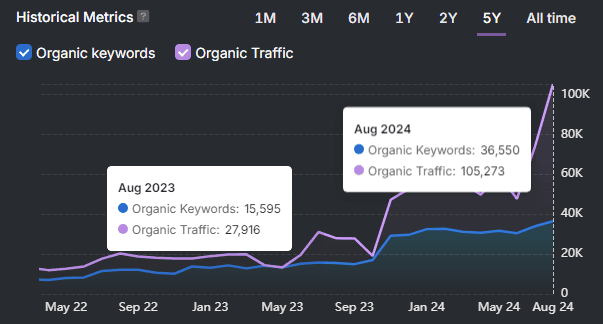
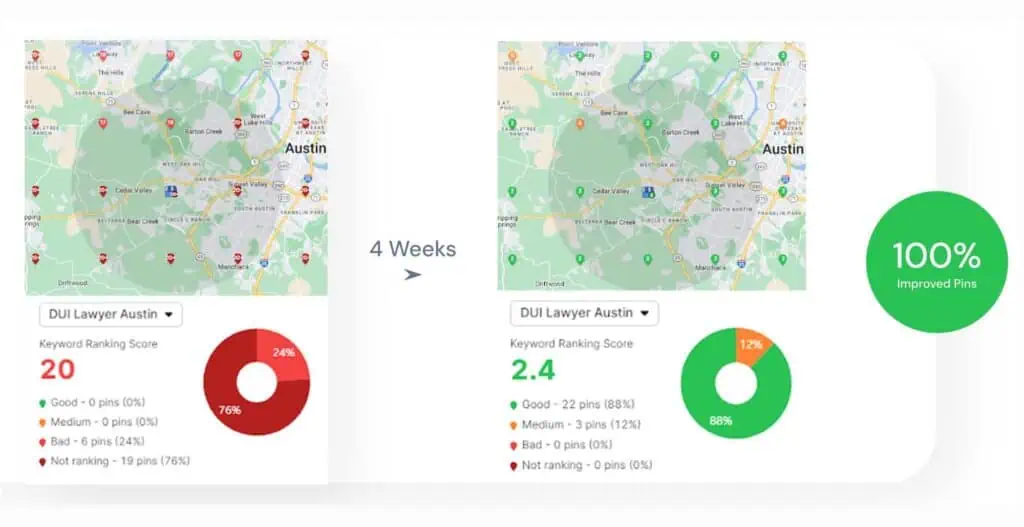
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}