

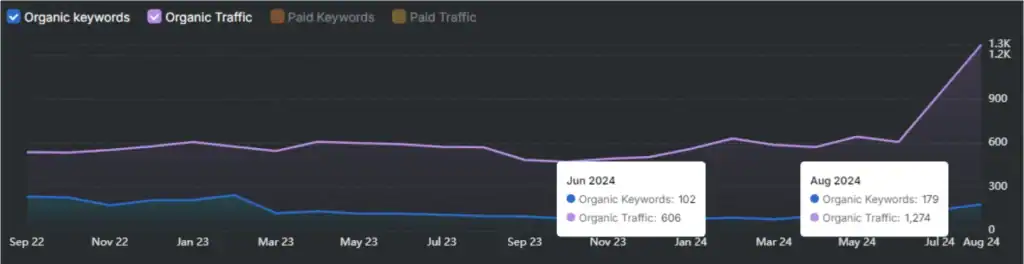
Large language models (LLMs) answer the same queries and repeat these answers with citations that point to external sources. LLMs reveal different citation structures, but the structure behind these citations remains unclear. This uncertainty shapes how researchers interpret LLM output and how SEO professionals judge source reliability.
This study evaluates citation behavior across 5,504,399 responses from 748,425 queries collected between August 25 and September 25, 2025. The dataset captures 3 (Gemini, OpenAI, Perplexity) systems with distinct retrieval conditions to evaluate how each model retrieves, selects, and attributes external sources.
The findings reveal clear structural differences in citation behavior, shaped by retrieval access, response length, and model design. These differences hold important implications for SEO strategy, brand visibility, and content discoverability in LLM-driven environments.
Methodology – How Was Citation Behavior Measured?
The study by Search Atlas analyzes citation behavior across 3 LLMs. Citation behavior refers to the way models select and reference external sources. Citation behavior matters because it determines content discoverability and information distribution in AI-mediated search.
The dataset contains 5,504,399 responses generated across 748,425 unique queries between August 25 and September 25, 2025. The dataset includes outputs from 3 production systems listed below.
- Perplexity Sonar. Retrieval-augmented generation with mandatory web search enabled
- Gemini 2.0 Flash-Lite. Parametric model without live retrieval
- OpenAI GPT-4o-mini. Parametric model without live retrieval
This configuration contrasts retrieval-driven and non-retrieval architectures in real usage settings. Real usage settings matter because they reveal how the systems behave outside controlled experiments.
All cited domains were standardized to a normalized domain.tld format. Standardization removes subdomain noise and ensures consistent measurement across models.
The filtering protocol retained only queries where all 3 models produced at least one citation. This filtering step ensures fair comparison and prevents inflated similarity caused by uneven citation patterns.
The study evaluates citation behavior through 3 primary metrics listed below.
- Domain Citation Count. Measures the number of unique domains cited per query.
- Jaccard Similarity. Computes the intersection divided by the union of cited-domain sets for each model pair. Jaccard Similarity shows how often the systems rely on the same external sources.
- Agreement Rate. Measures the percentage of queries where model pairs share at least one cited domain. The Agreement Rate establishes baseline source convergence.
Extended analyses examined response length (character count), citation density (citations per character), and URL freshness. These analyses evaluate whether verbosity, citation volume, or publication recency influences retrieval diversity and source overlap.
What Is the Final Takeaway?
The analysis shows that retrieval-augmented systems produce the broadest and most transparent citation patterns. Perplexity Sonar cites the highest number of unique domains per query while maintaining the shortest response length, achieving citation density 2 to 3 times higher than parametric models. This architecture prioritizes source attribution as core output.
Parametric models show systematic source preferences. Gemini and OpenAI GPT models demonstrate 42% domain overlap, which is the highest pairwise similarity the study observed. The overlap suggests convergent source selection from training data. Both systems cite fewer unique domains per query compared to retrieval-augmented alternatives.
Citation behavior exhibits strong query-type dependency. Brand-specific queries, local business queries, and single-source authority queries produce single citations across all models regardless of retrieval capability. Information structure constrains citation behavior more than model design for specific query classes.
Response length does not correlate with citation richness. Gemini produces responses exceeding 60,000 characters while citing fewer sources than Perplexity outputs under 2,000 characters. Citation density represents an independent architectural decision rather than an emergent property of response length.
Cross-model source agreement remains limited. Only 60% to 65% of queries produce at least 1 shared domain across all 3 systems, with 35% to 40% yielding completely disjoint source sets. LLM-mediated information retrieval creates multiple parallel information pathways rather than converging on canonical sources.
How Do LLMs Differ in Domain Citation Behavior?
I, Manick Bhan, together with the Search Atlas research team, analyzed domain-level citation patterns across 5,504,399 responses to understand how Perplexity, Gemini, and OpenAI reference external sources.
The goal is to show how often each system cites domains, how broadly each model retrieves sources, and how their citation structures differ when answering the same query.
Total Domains Cited by Each LLM
This analysis measures the total number of unique domains each model cites across all shared queries. Total domain count matters because it reflects the breadth of each model’s external sourcing.
The headline results are shown below.

- Perplexity total domains. Highest overall domain diversity
- OpenAI total domains. Moderate domain diversity
- Gemini total domains. Lowest domain diversity
Perplexity cites the widest set of domains. OpenAI maintains a balanced but narrower footprint. Gemini cites the smallest range of domains across the dataset.
Distribution of Domain Citations per Query
This distribution shows how many domains each model cites per query. Per-query volume reveals how frequently each model references one, several, or many sources when answering the same prompt.

Average Domains Cited per Query
This metric captures the average number of domains each model cites when all 3 produce domain-level citations for the same query. Average citation count shows how each system treats source diversity in controlled comparisons.
The headline results are shown below.

- Perplexity average. Highest average domains per query
- OpenAI average. Moderate but stable domain count
- Gemini average. Lowest domain count across shared queries
The median domains cited per query show typical citation behavior without distortion from extreme cases. The headline results are shown below.

- Perplexity median. Strong multi-domain tendency
- OpenAI median. Balanced single-plus citation pattern
- Gemini median. One-domain behavior dominates
Perplexity demonstrates the strongest multi-source retrieval signature. OpenAI shows steady but narrower sourcing. Gemini displays a concentrated pattern anchored in one primary domain per answer.
How LLM Models Agree on Cited Domains?
LLMs cite different domains and produce different citation structures. I, Manick Bhan, together with the Search Atlas research team, analyzed how Perplexity, Gemini, and OpenAI cite external domains when answering the same queries.
The analysis measures domain agreement through Jaccard similarity, agreement rate, and overlap distributions. The Jaccard similarity analysis measures how often 2 models cite the same domains for the same query to reveal whether systems retrieve convergent or divergent source sets.
The results below show where the models converge, where they diverge, and how retrieval access influences domain alignment.
Average Domain Overlap Between LLMs
Average domain overlap shows how often each model pair aligns on cited sources. The headline results are shown below.

- Gemini vs. OpenAI. Approximately 42% average overlap, the highest among all pairs
- Perplexity vs. Gemini. Lower overlap with greater dispersion
- Perplexity vs. OpenAI. Lower overlap with greater dispersion
Gemini and OpenAI form the most aligned pair. Their overlap indicates shared patterns in how parametric models select trusted domains. Pairs that include Perplexity show lower and more dispersed overlap because active web search widens its domain pool.
Agreement Rate Across Queries
Agreement rate measures the percentage of queries where each model pair shares at least one cited domain. The headline results are shown below.

- Most model pairs agree on at least one domain in 60 to 65% of queries.
- 35 to 40% of queries show no shared domains across pairs.
These results show partial convergence. Models often agree on at least one source but still produce many queries with completely distinct citation sets.
Distribution of Domain Overlap Scores
The overlap distribution reveals how stable domain agreement remains across queries.

- Gemini and OpenAI show the highest and most stable overlap scores.
- Pairs involving Perplexity show lower overlap and greater dispersion.
Perplexity is always-on web search retrieves a broader and more diverse set of sources. This behavior reduces strict agreement with Gemini and OpenAI but increases coverage of long-tail and newly emerging domains.
Domain Citations Overlap Between LLMs
The shared domain space across the 3 models remains narrow and highlights how each system contributes distinct citations even when answering identical prompts. The visualization below shows the shared and unique domains cited by Perplexity, OpenAI, and Gemini for the same queries.

What Do LLM Output Length and Citation Count Reveal?
LLMs produce very different output structures even when they answer the same queries. Citation count, citation density, and response length vary across Perplexity, Gemini, and OpenAI, which reveals how each system prioritizes attribution, verbosity, and source diversity.
The results below summarize these behavioral differences and show how model architecture shapes citation patterns.
Citation Count by Platform and Model
The citation-count analysis measures how frequently each system references external domains. Citation frequency matters because it shows whether attribution represents a core behavior or an optional feature. The headline results are shown below.

- Perplexity Sonar cites domains in almost every response and consistently returns the highest citation counts.
- Gemini-2.0-Flash-Lite shows the widest variance, with rare outliers exceeding 20+ citations for a single query.
- OpenAI GPT-4o-mini-2024-07-18 cites far less frequently than every other model and produces no extreme outliers.
- GPT-5-nano-2025-08-07 behaves similarly to Gemini but generates rare citation-heavy bursts.
Median citation values confirm the pattern.
- Perplexity maintains the highest medians, which shows that multi-source attribution represents its standard response behavior.
- Gemini and OpenAI show lower medians with occasional spikes, which indicates that high-citation events concentrate in narrow query classes.
Examples of Low-Citation Query Types
Certain prompt structures reliably produce one-domain outputs across all models. These prompts narrow the informational space, so one authoritative source satisfies the entire request.
The examples are shown below.

Single-citation behavior appears consistently across all models for specific query classes. The query classes are listed below.
- Local business queries cite only the official business website.
- Brand-specific product queries cite only the brand-owned domain.
- Instructional platform queries cite a single platform domain.
- Product review prompts cite one trusted review site.
Perplexity retains web search access, but retrieval does not expand citation breadth for these narrow query types. This pattern demonstrates that citation behavior responds to query structure and information topology.
Single authoritative sources satisfy information needs for these query types, which make multi-source citation unnecessary regardless of model capability. Web search enablement does not expand citations where the query structure implies that a single source is sufficient.
Response Length Across Models
Response length varies dramatically across systems. Verbosity matters because longer outputs offer more opportunities for citation, yet the models do not use this space in the same way.
The headline results are shown below.

- GPT-4o-mini remains concise
- GPT-5-nano produces moderately longer responses with higher variability.
- Perplexity Sonar produces the shortest and most consistent responses.
- Gemini-2.0-Flash-Lite generates the longest outputs by a wide margin, frequently exceeding 60,000 characters.
The relationship between length and citation behavior remains weak.
- Gemini produces expansive answers without additional attribution.
- Perplexity produces tight answers with dense attribution.
This pattern confirms that architecture (not response length) governs citation behavior.
What Should SEO Teams Do with These Findings?
SEO teams need to treat these results as guidance for strengthening content strategy, citation visibility, and competitive positioning across AI-generated environments. The recommendations to use these patterns effectively are listed below.
1. Optimize for RAG Systems
The citation dominance of Perplexity indicates that retrieval-augmented systems represent the next frontier for content discoverability. Adapt SEO strategies to optimize for real-time retrieval rather than static training data inclusion.
Firstly, implement structured data markup to enhance entity recognition and source authority signals during retrieval operations. Using Schema.org markup for articles, products, local businesses, and FAQs improves the probability of inclusion in retrieval-augmented system citations.
Secondly, maintain content freshness signals, which include publication dates, update timestamps, and temporal relevance markers. Retrieval systems prioritize recent content for queries with temporal sensitivity, which makes freshness a key ranking factor in LLM citation behavior.
Thirdly, build topical authority clusters through comprehensive coverage of related concepts within domains. Retrieval systems evaluate domain-level authority for topic areas, which make concentrated expertise more discoverable than superficial content.
2. Address Multi-Model Source Distribution
The 35% to 40% query proportion shows that there are completely disjoint source sets across models. This source set pattern shows SEOs need multi-platform optimization.
Firstly, diversify authority signals beyond traditional PageRank-style metrics. Different LLMs weigh authority signals differently. Community recognition, academic acknowledgement, and social media sharing all contribute to cross-model visibility.
Secondly, create content for different citation contexts. Parametric models favor sources present in training data (typically well-established domains with historical content), while retrieval systems surface recent, semantically relevant content. Maintain both archival authority and current coverage to maximize citation probability across architectures.
Thirdly, monitor LLM citation patterns directly rather than inferring from traditional search rankings. The 42% Gemini-OpenAI overlap suggests citation behavior diverges significantly from traditional search engine result pages (SERPs). Track which sources LLMs cite for target queries to understand actual visibility.
3. Leverage Query-Type Dependencies
Single-citation query patterns present opportunities for owned-media dominance.
Firstly, establish an official presence for brand queries. All models converge on official domains for brand-specific queries, which makes owned properties the primary citation source for these high-intent queries (commercial searches, purchase-oriented requests, transactional information needs).
Secondly, develop authoritative instructional content (guides, expert tutorials, canonical documentation) for platform-specific or methodology-specific queries. Domain operators who represent the authoritative source for a technique or tool receive exclusive citations regardless of alternative coverage.
Thirdly, optimize local business information across structured data sources. Local queries produce single citations to official business presences, which make consistent NAP (Name, Address, Phone) information and structured data critical for citation capture.
5. Prioritize Citation Density Over Content Length
The inverse relationship between verbosity and citation richness suggests strategic implications.
Firstly, avoid excessive content length that dilutes topical focus. The 60,000+ character responses of Gemini cite fewer sources than the concise outputs of Perplexity. Length does not improve citation probability and reduces focus signals that retrieval systems use for relevance scoring.
Secondly, structure content for extractive citation rather than comprehensive narratives. LLMs cite specific claims or data points rather than entire articles. Use clear topic sentences, structured headings, and discrete factual statements that enable extractive citation behavior.
Thirdly, develop modular content architectures that allow LLMs to cite specific sections or claims without requiring full-page attribution. Micropage structures and anchor-linkable subsections improve citation granularity.
6. Prepare for Source Fragmentation
Limited cross-model agreement indicates the emergence of parallel information ecosystems.
Firstly, expand beyond Google-centric SEO. Traditional search optimization focuses on Google ranking algorithms. LLM-mediated search creates multiple independent citation systems, each with distinct source preferences. Optimization requires multi-platform strategies rather than focusing on a single engine.
Secondly, develop direct LLM optimization metrics that include citation frequency, source diversity across models, and agreement rate for target queries. These metrics replace traditional ranking positions as primary performance indicators.
Thirdly, monitor training data inclusion for parametric models alongside retrieval optimization. The 42% Gemini-OpenAI overlap suggests they share training sources. Content present in model training data receives preferential citation from parametric systems regardless of recency.
What Are the Limitations of the Study?
Every study includes constraints. The limitations of this analysis are listed below.
- Temporal constraints. The 30-day collection window (August 25 to September 25, 2025) provides a snapshot of fast-moving systems. Model updates, data refresh cycles, and architectural revisions happen continuously. Citation patterns from this period do not remain stable as models evolve.
- Model configuration uncertainty. The comparison uses production systems with undisclosed internal settings. Perplexity uses mandatory web search, and the setting does not support disabling. This prevents a controlled comparison of retrieval-enabled versus retrieval-disabled behavior within the same model family.
- Limited model coverage. The analysis evaluates 3 model families and excludes other major deployment (Anthropic Claude, Cohere, and Meta Llama variants). Citation behavior observed in this subset does not generalize across the full LLM landscape.
- Correlation vs. causation. The observational design prevents causal attribution. Associations between architecture and citation behavior reflect either the architecture itself or confounding factors, which include query routing, content availability, and temporal variation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}