

Chunking is the process of dividing large documents into smaller, meaningful segments that AI systems index, embed, and retrieve for accurate response generation. Chunking LLM pipelines depend on this process because large language models operate within context limits and require focused inputs to generate correct answers. Chunking strategies for RAG define how information moves from raw documents into embeddings, vector storage, retrieval, and generation, which makes chunking a foundational layer in AI retrieval systems. Chunking strategies improve retrieval accuracy, reduce hallucinations, and ensure each retrieved segment contains complete and usable context.
Chunking strategies for RAG include multiple approaches that balance structure, meaning, and system performance across different use cases. Fixed-size chunking prioritizes speed and consistency, while recursive chunking preserves document structure through hierarchical splitting. Semantic chunking groups text by meaning using embeddings, and agentic chunking applies LLM reasoning to dynamically organize content. Hierarchical chunking separates retrieval and context layers, and late chunking preserves full-document context before segmentation. RAG chunking strategies differ because each method optimizes a different tradeoff between precision, coherence, and computational efficiency.
Chunk size, chunk overlap, and segmentation method directly control retrieval quality, answer accuracy, and system cost in AI retrieval. Chunk size determines whether retrieval favors precision or context completeness, while chunk overlap RAG strategies preserve boundary context by repeating 10–20% of content between chunks. Sliding window chunking and semantic segmentation maintain continuity, while poor chunking fragments meaning and reduces retrieval precision. Chunking strategies influence evaluation metrics like context precision, context recall, IoU, and answer accuracy, which makes chunking optimization essential for reliable RAG performance.
Chunking strategies evolve toward adaptive, model-aware, and dynamic systems that respond to document structure, query intent, and model capabilities. Chunking best practices focus on starting with simple baselines, applying hybrid methods, enriching chunks with metadata, and aligning chunking with real query patterns. Evaluation frameworks measure chunking performance using retrieval metrics and real-world queries, while observability tracks chunk effectiveness in production environments. Future chunking strategies shift toward adaptive chunking, agentic systems, hierarchical retrieval, and larger semantic units, where chunking remains a core mechanism for controlling accuracy, cost, and reasoning in AI retrieval systems.
What Is Chunking in AI Retrieval?
Chunking is the process of breaking down large documents into smaller, manageable segments called chunks that AI systems index, embed, and retrieve. Chunking definition in AI retrieval refers to creating segments that preserve meaning, fit model context windows, and remain usable as standalone retrieval units. Chunking meaning in RAG centers on semantic coherence, contextual preservation, and efficient retrieval across large document sets.
Why does chunking matter in AI retrieval and RAG? Chunking matters because large language models process limited context at one time. Large language models need chunking to pass relevant text into retrieval systems without sending entire documents. Chunking quality shapes retrieval accuracy because coherent chunks keep related facts together, while weak chunks split context and reduce precision.
How does chunking work inside the RAG pipeline? Chunking starts the RAG pipeline by turning raw documents into retrieval units for embedding and search. The pipeline follows 5 stages listed below.
1. Chunking
2. Embedding
3. Vector storage
4. Retrieval
5. Generation
Each chunk becomes a vector representation, and the vector database stores that representation for similarity search against user queries.
How does chunking connect to embeddings and retrieval accuracy? Chunking improves embedding quality because each chunk carries a focused unit of meaning. Focused chunks produce stronger vector representations, and stronger vector representations improve similarity matching during retrieval. Better retrieval passes more relevant context into generation, which improves response coherence, system efficiency, and answer quality in RAG workflows.
Why Does Chunking Strategy Matter for RAG Performance?
Chunking strategy matters for RAG performance because chunking quality determines retrieval accuracy, context relevance, and final answer correctness. Chunking in RAG acts as the primary control layer that shapes how information enters embedding, retrieval, and generation systems. Chunking impacts retrieval directly because poorly structured chunks reduce precision, while optimized chunks improve recall, coherence, and system efficiency.
Why is chunking the foundational determinant of RAG quality? Chunking in RAG defines how source data becomes retrievable knowledge units, which makes it the strongest driver of system performance. Chunking quality outweighs embedding model selection because embeddings rely on input structure. Poor chunking produces weak semantic signals, while strong chunking produces precise vector representations that improve downstream retrieval and generation.
Why does chunking directly impact retrieval accuracy and recall? Chunking impact retrieval by controlling chunk size, overlap, and structure, which increases recall by 10–15%. Small, focused chunks encode single ideas, which improves similarity matching during vector search. Structured chunking methods improve retrieval accuracy by 2–18% compared to baseline approaches, while late chunking improves accuracy by 10–12% in documents with complex references.
What role does chunking play in context preservation and hallucination reduction? Chunking quality preserves context inside each retrieval unit, which reduces hallucinations in generated responses. Small chunks lose context and produce shallow answers, while large chunks reduce retrieval precision because relevant details remain buried. Balanced chunking maintains semantic completeness and ensures relevant context reaches the language model without adding noise.
How does chunking affect LLM performance and efficiency? RAG performance chunking improves efficiency by limiting unnecessary context and reducing computation cost. Large language models lose accuracy with long inputs due to attention dilution and the lost in the middle effect. Smaller, relevant chunks reduce latency, improve response speed, and maintain reasoning accuracy by focusing only on necessary information.
Why does chunking improve business outcomes and user experience? Chunking quality improves user experience because it increases answer accuracy, speed, and relevance. Efficient chunking reduces processing overhead and prevents irrelevant retrieval, which lowers operational cost and increases satisfaction. Poor chunking increases noise in retrieval and reduces perceived system reliability.
Why does the chunking strategy require significant time and complexity? Chunking in RAG requires careful design because optimal chunk size and structure vary by document type and use case. Advanced strategies increase implementation complexity and infrastructure requirements. Chunking strategy selection depends on content structure, domain specificity, and retrieval goals, which makes it a high-impact optimization layer in RAG systems.
What are the Main Chunking Strategies?
There are 7 main chunking strategies for LLM and RAG pipelines that define how documents are segmented for retrieval and generation. Primary types of chunking determine how text is split, how meaning stays intact, and how retrieval systems access relevant information. The strategies are listed below.
1. Fixed-size (or Token) Chunking
2. Recursive Character Chunking
3. Semantic Chunking
4. Document-Based/Structural Chunking
5. Agentic Chunking
6. Hierarchical (Parent-Child) Chunking
7. Sliding Window Chunking
These chunking strategies define how information flows through RAG systems, and each strategy impacts retrieval precision, context preservation, and generation quality. Selecting the correct strategy depends on document structure, query type, and performance requirements.
1. Fixed-size (or Token) Chunking
Fixed-size chunking is a chunking strategy in RAG systems that divides text into uniform segments based on a defined token, character, or word count. Fixed-size chunking ensures each segment fits within model context limits and remains easy to index, embed, and retrieve. Fixed-size chunking includes optional overlap, which preserves context across boundaries and prevents sentence fragmentation.
What are the advantages of fixed-size chunking? Fixed-size chunking provides simplicity, predictability, and low computational cost in RAG pipelines. Fixed-size chunking enables consistent batch processing because every chunk follows the same size rules. Fixed-size chunking ensures compatibility with embedding models because chunk size stays within token limits, which improves processing speed and reduces latency.
What are the disadvantages of fixed-size chunking? Fixed-size chunking lacks semantic awareness, which reduces chunk coherence and retrieval precision. Fixed-size chunking splits text without considering sentence or topic boundaries, which fragments meaning across chunks. Fixed-size chunking lowers concept integrity because related information exists in separate segments, which weakens retrieval accuracy.
When should fixed-size chunking be used in RAG systems? Fixed-size chunking works best for homogeneous content, early-stage systems, and speed-focused pipelines. Fixed-size chunking fits logs, structured text, and simple documents because content does not depend on deep semantic relationships. Fixed-size chunking supports prototyping because implementation remains fast and predictable.
How should chunk size be selected in fixed-size chunking? Chunk size selection in fixed-size chunking starts with a baseline of 100–150 tokens or 500 characters and adjusts based on retrieval quality. Fixed-size chunking increases chunk size when context appears incomplete and decreases chunk size when irrelevant information appears. Fixed-size chunking performs best between 200–500 tokens with 10–20% overlap for general-purpose retrieval tasks.
What overlap strategy works best for fixed-size chunking? Overlap in fixed-size chunking preserves boundary context windows and prevents information loss between segments. Fixed-size chunking uses 15–20% overlap for general text, 10% overlap for structured code, and up to 25% overlap for long narrative content. Fixed-size chunking avoids overlap above 30% because redundancy increases storage and processing cost.
What performance factors affect fixed-size chunking? Fixed-size chunking achieves high performance through fast processing, low memory usage, and parallel execution. Fixed-size chunking processes streams with bounded memory using buffer plus chunk size limits. Fixed-size chunking supports parallelization across CPU cores, and character-based chunking delivers the fastest execution speed among chunking methods.
2. Recursive Character Chunking
Recursive chunking is a chunking strategy that breaks down large text into smaller segments using a hierarchical structure of natural separators. Recursive chunking preserves document structure by splitting content based on paragraphs, sentences, and words instead of fixed limits. Recursive chunking ensures each segment maintains logical flow and semantic integrity within RAG systems.
How does recursive chunking work step by step? Recursive chunking works by applying a hierarchy of separators that split text only when higher-level boundaries exceed size limits. The steps are listed below.
- Paragraph-level splitting processes text using double line breaks to preserve complete ideas.
- Sentence-level splitting activates when paragraphs exceed size constraints and maintains sentence integrity.
- Word-level splitting applies as a final step to meet strict size limits.
What are the main advantages of recursive chunking? Recursive chunking improves structural preservation and semantic coherence compared to fixed-size methods. Recursive chunking reduces context fragmentation by up to 40% because segments follow natural boundaries. Recursive chunking increases semantic clarity by 35% because each chunk reflects a complete thought.
What are the limitations of recursive chunking? Recursive chunking increases computational cost due to multi-step evaluation and hierarchical processing. Recursive chunking requires 200–400% more processing time because the system evaluates multiple splitting levels. Recursive chunking adds complexity to implementation because separator hierarchies must match document structure.
When should recursive chunking be used in RAG systems? Recursive chunking fits document types that require structure preservation and high retrieval accuracy. Recursive chunking works well for legal documents, technical manuals, and long-form content because meaning depends on structured context. Recursive chunking improves retrieval quality in systems where maintaining logical flow is critical.

3. Semantic Chunking
Semantic chunking is a chunking strategy that divides text into meaning-based segments using embedding similarity and contextual relationships. Semantic chunking groups sentences that share a common topic, which ensures each chunk represents a complete idea. Semantic chunking uses vector-based analysis to detect topic boundaries instead of relying on fixed-size rules.
How does semantic chunking identify topic boundaries? Semantic chunking identifies topic boundaries by measuring similarity between sentence embeddings and detecting sharp drops in similarity. Semantic chunking encodes sentences into vectors and calculates cosine similarity between consecutive pairs. Semantic chunking inserts boundaries when similarity falls below a dynamic threshold, typically set between 80–95% percentile of similarity scores.
What are the main types of semantic chunking? There are 2 primary types of chunking within semantic chunking, which define how segments form based on meaning. The types are listed below.
- Breakpoint-based semantic chunking detects topic shifts using similarity thresholds between adjacent sentence groups.
- Clustering-based semantic chunking groups semantically similar sentences, even when the sentences are not consecutive.
What limitations exist in traditional chunking methods? Traditional chunking methods reduce retrieval quality because they ignore semantic boundaries and split related concepts. The limitations are presented in the table below.
| Limitation Type | Description | Impact on AI Systems |
|---|---|---|
| Concept Splitting | Important concepts are divided across multiple chunks. | Degraded embeddings and incomplete retrieval. |
| Context Loss | Context does not persist across arbitrary splits. | Disjointed answers and lower relevance. |
| Noise Introduction | Unrelated content appears in the same chunk. | Reduced semantic clarity and higher topic entropy. |
| Structural Disruption | Text splits ignore document structure. | Broken references and misaligned information. |
When should semantic chunking be used in RAG pipelines? Semantic chunking works best for complex documents that contain frequent topic shifts and dense information. Semantic chunking fits legal documents, academic research, and technical manuals because meaning depends on context grouping. Semantic chunking improves retrieval precision for nuanced queries.
What are the computational challenges of semantic chunking? Semantic chunking increases computational cost and processing complexity due to embedding-based analysis. Semantic chunking requires 5–10x more ingestion computation because each sentence requires vector comparison. Semantic chunking requires parameter tuning to balance chunk size and coherence.
When is fixed-size chunking preferable to semantic chunking? Fixed-size chunking performs better for structured or repetitive content where semantic grouping adds no measurable benefit. Fixed-size chunking fits FAQs, standardized reports, and simple knowledge bases because related information already exists within fixed boundaries. Fixed-size chunking reduces compute cost and maintains comparable retrieval performance.
What are the best practices for optimizing semantic chunking? Semantic chunking optimization requires controlled experimentation with similarity thresholds and retrieval evaluation. The steps are listed below.
- Start with a threshold at the 95th percentile to detect strong topic shifts.
- Decrease the threshold gradually to increase chunk frequency if chunks remain too large.
- Evaluate retrieval performance using real queries after each adjustment.

4. Document-Based/Structural Chunking
Document-Based or Structural Chunking is a chunking strategy that divides text into segments based on a document’s inherent structure, using elements like headings, paragraphs, and formatting. Document-Based Chunking preserves logical organization and ensures each chunk reflects a complete structural unit. Document-Based Chunking applies to formats (PDF, DOCX, HTML, Markdown, LaTeX, code) where structure defines meaning and retrieval relevance.
What advantages does Document-Based Chunking provide? Document-Based Chunking preserves context, improves retrieval accuracy, and maintains logical flow across structured documents. Document-Based Chunking keeps paragraphs and sections intact, which ensures semantic completeness during embedding. Document-Based Chunking reduces token waste because only relevant structured segments enter retrieval and generation.
What disadvantages exist in Document-Based Chunking? Document-Based Chunking introduces variability in chunk size and increases implementation complexity. Document-Based Chunking creates uneven chunks because paragraph and section lengths vary. Document-Based Chunking risks exceeding token limits when large sections remain uncompressed, and Document-Based Chunking requires format-aware parsing logic.
When should Document-Based Chunking be used in RAG systems? Document-Based Chunking works best for structured documents where hierarchy and formatting define meaning. Document-Based Chunking fits legal contracts, research papers, financial reports, and technical manuals because sections and headings carry semantic importance. Document-Based Chunking improves retrieval quality when queries require full contextual passages instead of isolated sentences.
What are the main types of Document-Based Chunking? There are 5 primary types of chunking within Document-Based Chunking, which define how structure guides segmentation. The types are listed below.
- Paragraph-based chunking divides text using paragraph boundaries to preserve full ideas.
- Recursive chunking splits sections hierarchically until size constraints are met.
- Document-specific chunking adapts segmentation rules to document format elements (tables, headings, lists).
- Section-level chunking groups content by headings and document sections.
- Page-level chunking treats each page as a standalone chunk with fixed boundaries.
What are the best practices for implementing Document-Based Chunking? Document-Based Chunking requires structure-aware parsing, controlled chunk size, and iterative evaluation. The steps are listed below.
- Analyze document structure to identify headings, paragraphs, and formatting elements.
- Select a chunk size that fits embedding limits (256–1024 tokens) while preserving context.
- Apply an overlap of 10–20% to maintain continuity across boundaries.
What common mistakes should be avoided in Document-Based Chunking? Document-Based Chunking fails when structure is ignored or when a single strategy applies to all document types. Document-Based Chunking loses effectiveness when parsing fails to detect headings or sections. Document-Based Chunking produces inconsistent results when one method applies to diverse formats without adjustment.
5. Agentic Chunking
Agentic Chunking is a chunking strategy that uses a Large Language Model to dynamically group text into semantically coherent segments based on meaning and context. Agentic Chunking delegates segmentation decisions to an AI system that analyzes relationships between text units. Agentic Chunking improves chunking quality by aligning segmentation with content structure, query intent, and retrieval goals.
What is the core process of Agentic Chunking? Agentic Chunking follows a multi-step pipeline where small text units are grouped into meaningful chunks using LLM reasoning. The steps are listed below.
- Mini-chunk creation splits documents into small units (around 300 characters) using recursive splitting.
- LLM grouping analyzes adjacent mini-chunks and merges semantically related units into larger chunks.
- Chunk assembly forms final chunks with controlled size limits and optional overlap for continuity.
What benefits does Agentic Chunking provide in RAG systems? Agentic Chunking improves retrieval accuracy, semantic coherence, and answer completeness in RAG pipelines. Agentic Chunking keeps related ideas together, which reduces fragmentation and improves embedding quality. Agentic Chunking reduces incorrect assumptions by up to 92% because chunks contain complete context instead of isolated fragments.
When should Agentic Chunking be used in RAG pipelines? Agentic Chunking works best for complex, unstructured, or high-stakes documents that require deep context and multi-section reasoning. Agentic Chunking fits legal texts, technical manuals, research papers, and enterprise knowledge bases because answers often span multiple sections. Agentic Chunking improves performance when queries require combining definitions, exceptions, and procedures.
When should simpler chunking methods be preferred? Simpler chunking methods perform better when documents are short, uniform, or do not require deep semantic grouping. Fixed-size chunking or recursive chunking reduces cost and complexity in these scenarios. Simpler methods maintain acceptable retrieval quality when context relationships remain straightforward.
What challenges exist in Agentic Chunking? Agentic Chunking increases implementation complexity, computational cost, and system dependencies on LLM behavior. Agentic Chunking requires prompt design, validation logic, and fallback mechanisms to ensure reliability. Agentic Chunking introduces higher latency and infrastructure cost because chunking includes LLM processing during ingestion.
6. Hierarchical (Parent-Child) Chunking
Hierarchical (Parent-Child) Chunking is a chunking strategy that splits documents into large parent chunks and smaller child chunks to optimize both retrieval precision and context quality. Hierarchical (Parent-Child) Chunking separates retrieval and generation roles by using small chunks for search and large chunks for context. Hierarchical (Parent-Child) Chunking improves RAG performance by balancing speed, accuracy, and scalability.
What is the core mechanism of Hierarchical (Parent-Child) Chunking? Hierarchical (Parent-Child) Chunking works by embedding child chunks for retrieval and returning the associated parent chunk for generation. Hierarchical (Parent-Child) Chunking creates parent chunks around 1500 tokens and child chunks around 200–400 tokens. Hierarchical (Parent-Child) Chunking retrieves relevant child chunks through vector search and then maps them to their parent chunk for full-context input to the LLM.
How is Hierarchical (Parent-Child) Chunking implemented? Hierarchical (Parent-Child) Chunking requires separate storage for child embeddings and parent content with linked identifiers. Hierarchical (Parent-Child) Chunking stores child vectors in databases (Pinecone, Chroma, Milvus) and stores parent content in structured storage (Postgres, in-memory stores). Hierarchical (Parent-Child) Chunking connects child chunks to parent chunks through metadata IDs to maintain relationships.
What advantages does Hierarchical (Parent-Child) Chunking provide? Hierarchical (Parent-Child) Chunking increases retrieval speed, improves context quality, and reduces hallucinations. Hierarchical (Parent-Child) Chunking achieves 5–10x faster retrieval because vector search operates on small child chunks. Hierarchical (Parent-Child) Chunking improves answer completeness because the LLM receives full parent context instead of fragmented segments.
What additional benefits does Hierarchical (Parent-Child) Chunking provide? Hierarchical (Parent-Child) Chunking improves recall, reduces token usage, and preserves semantic relationships. Hierarchical (Parent-Child) Chunking retrieves targeted information and expands context only when needed, which reduces token usage by up to 85–90%. Hierarchical (Parent-Child) Chunking maintains logical relationships between sections, which improves reasoning across complex documents.
When should Hierarchical (Parent-Child) Chunking be used? Hierarchical (Parent-Child) Chunking works best in production RAG systems that require both high precision and deep contextual understanding. Hierarchical (Parent-Child) Chunking fits large structured documents (legal contracts, textbooks, technical manuals) because queries range from detailed to summary-level. Hierarchical (Parent-Child) Chunking supports real-time systems where latency and accuracy both matter.
What challenges exist in Hierarchical (Parent-Child) Chunking? Hierarchical (Parent-Child) Chunking increases implementation complexity and requires careful boundary design. Hierarchical (Parent-Child) Chunking depends on accurate parent-child relationships, which require structured parsing and metadata management. Hierarchical (Parent-Child) Chunking risks exceeding context limits if parent chunks become too large.
What are the storage and cost implications of Hierarchical (Parent-Child) Chunking? Hierarchical (Parent-Child) Chunking increases storage requirements and adds ingestion cost due to dual-layer storage. Hierarchical (Parent-Child) Chunking requires storing both parent content and child embeddings, which doubles storage compared to single-layer chunking. Hierarchical (Parent-Child) Chunking adds ingestion costs of $0.01–$0.02 per document for enrichment and processing.
7. Sliding Window Chunking
Sliding Window Chunking is a chunking strategy that splits text into fixed-size segments with overlapping regions to preserve context between adjacent chunks. Sliding Window Chunking moves a defined window across text and creates overlapping segments that maintain continuity. Sliding Window Chunking ensures that information near chunk boundaries appears in multiple chunks, which improves retrieval consistency.
What is the mechanism of Sliding Window Chunking? Sliding Window Chunking works by moving a fixed-size window across text with a defined overlap between consecutive segments. Sliding Window Chunking uses a window size (300–600 tokens) and an overlap (10–25%) to duplicate boundary content. Sliding Window Chunking adjusts the stride based on overlap, where the stride equals the window size minus the overlap.
How does semantic Sliding Window Chunking function? Semantic Sliding Window Chunking extends the base method by using embedding similarity to detect natural breakpoints within the sliding window. Semantic Sliding Window Chunking compares token embeddings and identifies local similarity drops to define chunk boundaries. Semantic Sliding Window Chunking removes the need for fixed thresholds and adapts dynamically to content structure.
What benefits does Sliding Window Chunking provide in RAG systems? Sliding Window Chunking improves context continuity, retrieval accuracy, and boundary coverage in RAG pipelines. Sliding Window Chunking prevents boundary loss by ensuring key phrases appear in multiple chunks. Sliding Window Chunking increases dense retrieval precision by approximately 14.5% when the overlap ranges from 10–20%.
What are the disadvantages of Sliding Window Chunking? Sliding Window Chunking increases storage cost and introduces redundancy due to overlapping segments. Sliding Window Chunking creates duplicate content across chunks, which expands index size and retrieval noise. Sliding Window Chunking lacks semantic awareness, which causes mid-sentence splits and reduces coherence.
When should Sliding Window Chunking be used? Sliding Window Chunking works best for unstructured or noisy documents where structure is unreliable or missing. Sliding Window Chunking fits OCR text, scraped web pages, and large uniform corpora because consistent segmentation ensures coverage. Sliding Window Chunking improves performance in systems where avoiding boundary loss is critical.
What are the best practices for implementing Sliding Window Chunking? Sliding Window Chunking requires a controlled window size, balanced overlap, and structure-aware preprocessing. The steps are listed below.
- Set chunk size between 300–600 tokens and overlap between 10–25% based on content density.
- Apply structure-aware cleaning to remove boilerplate content (headers, footers, navigation).
- Maintain safety margins below model token limits (for example, target 480 tokens for a 512-token limit).
How Do You Choose the Right Chunking Strategy for Your Use Case?
You choose the right chunking strategy by aligning chunking with data type, query intent, model constraints, and retrieval goals to maximize RAG performance. Chunking best practices focus on matching chunk structure to how information is stored, searched, and generated. Production RAG chunking depends on optimizing chunking quality because chunking directly controls retrieval accuracy, latency, and hallucination rates.
What factors determine the best chunking strategy? There are 6 core factors that define chunking optimization in RAG systems. The factors are listed below.
- Data type defines structure and determines whether chunking follows format or meaning.
- The embedding model defines token limits and influences chunk size constraints.
- Query type defines granularity and determines chunk size requirements.
- Use case defines retrieval behavior (search, QA, generation, agents).
- Performance requirements define latency, cost, and scalability tradeoffs.
- Debugging needs define transparency and traceability of chunk outputs.
How does data type influence chunking selection? Data type determines whether chunking follows structure, semantics, or fixed rules. Long documents require chunking to fit model limits, while short content does not require chunking. Structured documents (PDF, HTML, Markdown, code) require Document-Based Chunking to preserve headings, tables, and sections.
How do embedding models affect the chunking strategy? Embedding models define maximum token limits and influence chunk size boundaries. Smaller context models require smaller chunks to avoid truncation, while larger context models allow larger chunks with richer context. Domain-specific embedding models require chunking aligned with content type (legal, medical, code).
How do query types affect chunking optimization? Query type determines whether chunking prioritizes precision or context depth. Short factual queries require small chunks for precise retrieval. Complex analytical queries require larger chunks to preserve relationships across multiple concepts.
How does a use case influence production RAG chunking? Use case determines how retrieved chunks are consumed in downstream systems. Search systems require smaller, focused chunks, while question answering and generation systems require larger, context-rich chunks. Agentic workflows require semantically grouped chunks for reasoning across multiple sections.
What is the impact of chunk size on RAG performance? Chunk size directly affects retrieval accuracy, latency, and cost in RAG systems. Small chunks improve precision but lose context, while large chunks preserve context but introduce noise and increase cost. Optimal chunking balances size to ensure each chunk forms a complete, standalone idea.
When should larger chunks be used? Larger chunks work best when context and relationships between ideas are critical. Larger chunks improve performance for narratives, arguments, and multi-step reasoning tasks. Larger chunks reduce fragmentation when concepts span multiple sentences or sections.
What are the best practices for production RAG systems? There are 6 chunking best practices that define effective chunking optimization. The practices are listed below.
- Start with fixed-size chunking (200–500 tokens, 10–20% overlap) as a baseline.
- Preserve semantic boundaries by aligning chunks with sentences or paragraphs.
- Use hybrid chunking when documents contain mixed structures or formats.
- Add metadata (section title, document type, source) to improve retrieval filtering.
- Evaluate chunking using real queries and measure retrieval performance.
- Iterate continuously based on feedback and system performance metrics.
How does overlap influence chunking performance? Overlap preserves boundary context but increases redundancy and cost. Overlap between 10–20% ensures continuity across chunks without excessive duplication. Lower overlap improves efficiency, while higher overlap increases retrieval coverage but expands index size.
How does continuous optimization improve chunking? Chunking optimization improves RAG performance through iterative testing and feedback loops. Continuous evaluation identifies weak chunks and adjusts size, overlap, or strategy. Production RAG chunking relies on monitoring retrieval accuracy and refining chunking based on real-world usage patterns.
What Is the Optimal Chunk Size for RAG Systems?
The optimal chunk size for RAG systems is the size that balances retrieval precision, context completeness, and computational efficiency, typically ranging from 200 to 1024 tokens depending on the use case. Chunk size defines how much information each chunk contains and directly impacts retrieval accuracy, response quality, and latency. Chunk overlap and sliding window chunking further refine chunk size by preserving context across boundaries.
What chunk size works best for different RAG scenarios? There are 3 primary chunk size ranges that define optimal chunking based on query type and content. They are listed below.
- Small chunks (128–256 tokens) optimize precision for fact-based queries and structured data.
- Medium chunks (256–512 tokens) balance context and precision for general-purpose RAG systems.
- Large chunks (512–1024 tokens) maximize context for complex reasoning and narrative content.
How does chunk size affect retrieval accuracy and context? Chunk size controls the tradeoff between precision and context retention in RAG systems. Small chunks isolate specific facts, which improves similarity matching but risks missing context. Large chunks preserve full ideas, which improves answer completeness but introduces noise and reduces retrieval precision.
What role does chunk overlap play in optimal chunk size? Chunk overlap preserves boundary context and ensures continuity between adjacent chunks in RAG systems. Chunk overlap RAG strategies typically use 10–20% overlap to duplicate critical boundary information. Chunk overlap prevents information loss when key phrases appear at chunk edges, especially in sliding window chunking setups.
How does sliding window chunking influence chunk size selection? Sliding window chunking uses fixed chunk sizes with overlap to maintain consistent segmentation and context continuity. Sliding window chunking ensures that each segment shares context with neighboring segments, which improves retrieval coverage. Sliding window chunking works best with moderate chunk sizes (300–600 tokens) and controlled overlap.
How does chunk size impact performance and cost? Chunk size directly affects latency, token usage, and system efficiency in RAG pipelines. Larger chunks increase token consumption and slow response time, while smaller chunks reduce cost but require retrieving more segments. Optimal chunking balances chunk size to minimize unnecessary tokens while preserving useful context.
How should chunk size be optimized in production RAG systems? Chunking best practices define chunk size through testing, evaluation, and iterative refinement based on real queries. The steps are listed below.
- Start with 200–500 tokens and 10–20% chunk overlap as a baseline.
- Increase chunk size if responses lack context or completeness.
- Decrease chunk size if retrieval returns irrelevant or noisy results.
How Does Chunk Overlap Improve Retrieval Quality?
Chunk overlap improves retrieval quality by repeating boundary content between adjacent chunks to prevent information loss and preserve semantic continuity. Chunk overlap ensures that concepts split across chunk boundaries remain fully represented in at least one chunk. Chunk overlap RAG strategies directly increase recall by maintaining complete ideas within retrievable units.
What is the purpose of chunk overlap in RAG systems? Chunk overlap prevents boundary loss by duplicating critical text between neighboring chunks. Chunk overlap ensures that definitions, steps, or relationships spanning two chunks remain intact. Chunk overlap maintains continuity so that retrieval systems access complete semantic units instead of fragmented text.
When does chunk overlap improve retrieval performance? Chunk overlap improves performance in scenarios where fixed-size chunking splits text mid-sentence or across related ideas. Chunk overlap works best for documents with cross-sentence dependencies (definitions, procedures, requirements). Chunk overlap becomes critical for smaller embedding models because limited context windows require stronger boundary preservation.
How does chunk overlap impact retrieval metrics? Chunk overlap increases recall and improves precision when applied at moderate levels. Chunk overlap improves recall from 77.1% to 82.4% in tested configurations with 125-token overlap. Chunk overlap RAG setups increase dense retrieval precision by approximately 14.5% when overlap is introduced.
What are the downsides of chunk overlap? Chunk overlap increases redundancy, storage cost, and retrieval noise when applied excessively. Chunk overlap creates near-duplicate chunks, which leads to repeated results in retrieval. Chunk overlap increases token usage and computational load, which reduces efficiency and lowers IoU scores in some benchmarks.
What are the best practices for chunk overlap in RAG systems? There are 4 chunk overlap best practices that define effective chunk overlap RAG implementation. They are listed below.
- Use 10–20% overlap for general text to balance continuity and efficiency.
- Increase overlap to 15–25% for technical or code-based content with dependencies.
- Apply 30–50% overlap for legal or scientific documents that require maximum context preservation.
- Monitor retrieval logs and reduce overlap if duplicate chunks dominate results.
How should chunk overlap be optimized in production RAG systems? Chunk overlap optimization requires iterative testing based on retrieval quality and efficiency metrics. Chunk overlap should increase when boundary loss appears in results and decrease when redundancy affects performance. Chunk overlap works best when combined with sliding window chunking to maintain consistent segmentation and context continuity.
How Do You Evaluate Chunking Strategy Performance?
You evaluate chunking strategy performance by measuring how chunking impacts retrieval accuracy, token relevance, and end-to-end RAG output quality. Evaluate chunking strategy effectiveness using chunking metrics that reflect both retrieval behavior and generation outcomes. RAG evaluation focuses on whether relevant information appears in retrieved chunks and improves final answers.
What metrics are used to evaluate chunking strategy performance? 10 core chunking metrics define RAG evaluation and chunking performance. They are listed below.
- Recall measures how many relevant tokens or chunks are retrieved from the total available relevant information.
- Precision measures how many retrieved tokens or chunks are actually relevant.
- The F1 score combines precision and recall into a single balanced metric.
- Intersection over Union (IoU) measures overlap between retrieved tokens and relevant tokens.
- PrecisionΩ measures maximum achievable precision assuming perfect recall.
- Recall@k measures how many relevant chunks appear in the top k retrieved results.
- Mean Reciprocal Rank (MRR) measures how early the first relevant chunk appears.
- Normalized Discounted Cumulative Gain (NDCG) measures the ranking quality of retrieved chunks.
- Context precision recall measures how well retrieved chunks match the required answer context.
- Answer accuracy measures how correctly the final response aligns with ground truth.
What additional operational metrics evaluate chunking performance? There are 4 operational metrics that define system-level chunking performance. The metrics are listed below.
- Latency measures response time for retrieval and generation.
- Cost measures token usage and infrastructure expense.
- Throughput measures how many queries the system processes over time.
- Resource utilization measures CPU, memory, and storage efficiency.
What methodology ensures accurate chunking evaluation? Chunking evaluation requires isolating chunking as the only variable while keeping all other RAG components constant. Evaluate chunking strategy by fixing documents, embedding model, retriever, and queries, then varying only chunking parameters. Run the same query set across different chunking strategies and compare performance using consistent metrics.
What role does token-level evaluation play in chunking metrics? Token-level evaluation measures relevance at the token level instead of the document level to reflect LLM behavior. Token-level metrics evaluate how much of the retrieved text directly contributes to the correct answer. Token-level evaluation improves accuracy because RAG systems consume partial documents rather than full documents.
What are the best practices for evaluating chunking strategy in production RAG systems? There are 5 chunking best practices that define effective RAG evaluation workflows. They are listed below.
- Start with a baseline (fixed-size chunking at 200–500 tokens with 10–20% overlap).
- Test multiple chunk sizes and strategies using the same dataset and queries.
- Combine quantitative metrics with human or LLM-based evaluation.
- Use real user queries or golden datasets for realistic performance measurement.
- Continuously monitor and refine chunking based on production feedback.
What Are the Best Tools and Libraries for Implementing Chunking Strategies?
There are 5 main tools and libraries for implementing chunking strategies that are listed below and cover full frameworks and lightweight solutions. The chunking ecosystem offers tools ranging from full frameworks to lightweight dedicated libraries that support chunking best practices and production RAG chunking.
- LangChain is a framework that provides flexible text splitting utilities through modular components for RAG pipelines. LangChain includes TextSplitters (RecursiveCharacterTextSplitter, SemanticChunker) that define how documents are segmented. LangChain supports custom splitters, which enable chunking optimization within larger workflows that include retrieval and generation.
- LlamaIndex is a data framework designed specifically for RAG pipelines that structures documents into optimized retrieval units called Nodes. LlamaIndex uses NodeParsers to create chunks that align with ingestion and retrieval requirements. LlamaIndex improves RAG performance because chunking integrates directly with indexing and query pipelines.
- chonkie is a lightweight chunking library that focuses exclusively on text splitting for simple and efficient integration. chonkie provides SemanticChunker implementations that group text based on meaning. chonkie reduces system overhead because it isolates chunking without requiring a full RAG framework.
- Haystack is an open-source NLP framework that includes built-in chunking strategies within end-to-end retrieval pipelines. Haystack supports length-based and semantic chunking within ingestion pipelines, document stores, retrievers, and readers. Haystack enables production RAG chunking by integrating chunking with search and QA systems.
- Custom implementation is a chunking approach where developers build fixed-size or recursive chunking logic directly in code for full control. Custom implementation defines chunk size, overlap, and splitting rules without external dependencies. Custom implementation improves transparency because every chunking decision remains fully configurable.
Library selection depends on project scope, framework preference, and level of customization needed.
What Are the Best Practices for Chunking in Production RAG Systems?
There are 7 chunking best practices for production RAG systems that define how to optimize chunking for accuracy, scalability, and efficiency. Production RAG chunking requires iterative optimization because chunking quality directly impacts retrieval and generation performance. The best practices are listed below.
- Start simple is a chunking best practice that establishes a baseline using fixed-size or recursive chunking before introducing complex methods. Starting simple ensures measurable performance benchmarks because baseline chunking provides a reference for comparison. Starting simple improves chunking optimization because retrieval accuracy is evaluated before adding complexity.
- Hybrid approaches excel is a chunking best practice that combines multiple chunking strategies based on content type. Hybrid approaches apply semantic chunking for narrative text, structural chunking for tables, and recursive chunking for code. Hybrid approaches improve retrieval quality because each content type uses the most effective segmentation method.
- Add metadata enrichment is a chunking best practice that enhances chunks with contextual attributes for better retrieval. Metadata enrichment includes headings, document titles, timestamps, and source identifiers. Metadata enrichment improves disambiguation and traceability because retrieval systems filter and rank chunks using additional signals.
- Scale considerations are a chunking best practice that prioritizes efficiency and speed for large-scale systems. Scale considerations favor deterministic and lightweight chunking methods when processing millions of documents. Scale considerations reduce indexing latency and maintain throughput in high-volume production environments.
- Continuous monitoring is a chunking best practice that tracks real-world performance and adapts chunking strategies over time. Monitor continuously evaluates retrieval accuracy using live queries and production data. Monitor continuously improves chunking optimization because strategies evolve based on observed performance.
- Preserving context at boundaries is a chunking best practice that prevents information loss at chunk edges. Preserving context at boundaries uses chunk overlap, contextual descriptions, or chunk expansion to maintain continuity. Preserving context at boundaries improves retrieval completeness because boundary information remains accessible.
- Match strategy to query patterns is a chunking best practice that aligns chunking with how users search and retrieve information. Match strategy to query patterns adjusts chunk size and structure based on query complexity. Match strategy to query patterns improves RAG performance because chunking aligns with real user intent.
No universal strategy exists for chunking in production RAG systems because optimal chunking depends on data, queries, and system constraints.
What Are the Limitations and Tradeoffs of Different Chunking Strategies?
There are 30 key limitations and tradeoffs of different chunking strategies that define how chunking impacts RAG performance, accuracy, and cost. Chunking tradeoffs emerge because chunking balances precision, context, efficiency, and scalability across different systems. The limitations and tradeoffs are listed below.
General Limitations of Chunking in RAG
- Chunk Size Balance is a limitation where chunk size creates a tradeoff between precision and context. Chunk Size Balance affects retrieval because small chunks improve precision while large chunks improve context.
- Embedding Model Context Windows is a limitation where model token limits restrict chunk size and context depth. Embedding Model Context Windows force truncation when chunks exceed limits, which reduces retrieval quality.
- Information Relevance is a limitation where chunks contain irrelevant or noisy content. Information Relevance decreases because larger chunks dilute important signals.
- Imprecise search results are a limitation where poor chunking reduces retrieval accuracy. Imprecise Search Results occur because chunks fail to align with the query intent.
- Latency and Cost is a limitation where larger chunks increase token usage and processing time. Latency and cost rise because more tokens enter the embedding and generation pipelines.
- Lost-in-the-Middle Problem is a limitation where important information becomes inaccessible in long contexts. The Lost-in-the-Middle Problem reduces model attention to mid-segment content.
- Semantic Similarity vs Practical Relevance is a limitation where embeddings match meaning but not task intent. Semantic Similarity vs Practical Relevance leads to irrelevant but semantically similar results.
- Embedding Bias Towards Shorter Texts is a limitation where shorter chunks rank higher in similarity search. Embedding Bias Towards Shorter Texts skews retrieval toward incomplete information.
- Incomplete Context from Single Chunks is a limitation where one chunk lacks full information. An incomplete context reduces answer completeness when queries span multiple chunks.
- Lack of Transparency in Embedding-Based Similarity is a limitation where retrieval decisions are not explainable. Lack of transparency makes debugging difficult.
- Traditional Search Outperforming Semantic Search is a limitation where keyword search outperforms embeddings in some cases. Traditional Search Outperforming Semantic Search occurs in exact-match scenarios.
- RAG Limitations is a limitation where chunking interacts with retrieval and generation weaknesses. RAG Limitations amplify hallucinations when chunking fails.
- Performance vs Quality is a limitation where improving retrieval quality increases cost and latency. Performance vs Quality forces tradeoffs in production systems.
- No Universal Winner is a limitation where no single chunking strategy works for all use cases. No Universal Winner requires case-by-case optimization.
- Document Type Specificity is a limitation where chunking must adapt to content structure. Document Type Specificity increases complexity in multi-format systems.
- Query Pattern Specificity is a limitation where chunking must align with query behavior. Query Pattern Specificity affects chunk size and structure decisions.
- Computational Cost is a limitation where advanced chunking increases processing requirements. Computational Cost rises with semantic and LLM-based methods.
- Implementation Complexity is a limitation where advanced strategies require more engineering effort. Implementation Complexity increases maintenance and debugging effort.
- The impact of the Chunking Strategy is a limitation where chunking strongly influences overall RAG performance. The impact of the Chunking Strategy makes chunking a critical dependency.
- Overlap is a limitation where chunk overlap increases redundancy and storage cost. Overlap improves recall but reduces efficiency.
- Chunk Size and Recall is a limitation where chunk size directly affects recall rates. Chunk Size and Recall require tuning to balance completeness and precision.
- Embedding Model Impact is a limitation where embedding quality influences chunking effectiveness. Embedding Model Impact outweighs chunking improvements.
Specific Strategy Limitations
- Fixed-Size Chunking is a limitation where fixed boundaries ignore semantic structure. Fixed-Size Chunking splits sentences and reduces coherence.
- Sentence-Based Chunking is a limitation where sentence-level splits lose broader context. Sentence-Based Chunking reduces multi-sentence reasoning.
- Paragraph-Based Chunking is a limitation where paragraph size varies significantly. Paragraph-Based Chunking creates inconsistent chunk sizes.
- Sliding Window Chunking is a limitation where overlap creates redundancy and duplicate retrieval. Sliding Window Chunking increases storage and noise.
- Semantic Chunking is a limitation where embedding-based grouping increases computational cost. Semantic Chunking requires tuning and does not always outperform simpler methods.
- Recursive Chunking is a limitation where hierarchical splitting increases processing overhead. Recursive Chunking depends on document structure quality.
- Contextual Chunking with LLMs is a limitation where LLM calls increase latency and cost. Contextual Chunking requires prompt design and infrastructure.
- Hybrid Chunking is a limitation where combining methods increases system complexity. Hybrid Chunking requires coordination across multiple strategies.
Post-Processing and Emerging Tradeoffs
- Chunk Expansion is a tradeoff where retrieving neighboring chunks increases context but adds cost. Chunk Expansion improves completeness but increases token usage.
- Lack of Advanced Text Segmentation is a limitation where current methods fail to fully model document meaning. Lack of Advanced Text Segmentation highlights the need for better segmentation models.
These limitations and tradeoffs show that chunking optimization in RAG systems requires balancing accuracy, cost, and complexity rather than selecting a single best method.

Does Chunking Influence Citation Accuracy in RAG?
Yes, chunking influences citation accuracy in RAG because chunking determines how complete, stable, and traceable source information remains during retrieval. Chunking controls whether citations point to full, coherent evidence or fragmented text segments. Chunking directly affects citation reliability because incomplete or split context leads to inaccurate or misleading references.
How does chunking affect citation stability? Chunking affects citation stability by defining how references map to source locations. Document-Based Chunking with page-level boundaries produces stable citations because each chunk aligns with fixed document positions. Fixed-size chunking produces unstable citations because chunk boundaries shift based on token size, which changes reference locations.
How does chunking impact citation completeness? Chunking impacts citation completeness by determining whether all relevant information exists within a single chunk. Poor chunking splits definitions, conditions, or exceptions across multiple chunks, which results in partial citations. High-quality chunking preserves full semantic units, which ensures citations include complete and accurate information.
What evidence shows chunking improves citation accuracy? Chunking quality improves citation accuracy by preserving critical context within retrieval units. Adaptive Chunking achieved 87% medical accuracy (p = 0.001) because it kept directives and exceptions within single chunks. Large chunking with overlap achieved 100% accuracy in one study because it prevented “buried clause” issues that occur with smaller chunks.
How does poor chunking reduce citation accuracy? Poor chunking reduces citation accuracy by truncating or fragmenting important information. Fixed-size chunking achieved only 50% accuracy in medical contexts because timing and safety details were split. Small chunks improve precision for narrow queries but fail for broader queries because the required context spans multiple chunks.
What is the relationship between chunk size and citation accuracy? Chunk size influences citation accuracy by balancing precision and contextual completeness. Small chunks isolate details but lose surrounding context, while large chunks preserve full meaning but introduce noise. Optimal chunking ensures that each chunk contains a complete, self-contained reference unit.
Can Poor Chunking Cause Hallucinations in RAG Systems?
Yes, poor chunking causes hallucinations in RAG systems because poor chunking breaks semantic coherence and prevents the retrieval of complete information. Poor chunking splits related concepts across multiple chunks, which forces the model to generate missing context. Poor chunking increases hallucinations because the model fills gaps when retrieval fails to provide full evidence.
How does poor chunking create hallucinations in RAG? Poor chunking creates hallucinations by fragmenting meaning and weakening retrieval signals. Poor chunking splits sentences or concepts (for example, splitting a definition across chunks), which reduces embedding quality. Poor chunking makes retrieval return incomplete evidence, which leads the model to generate incorrect or fabricated details.
What evidence shows chunking affects hallucination rates? Chunking quality directly correlates with answer accuracy and hallucination reduction. Adaptive chunking achieved 87% accuracy compared to 13% for fixed-size chunking in a clinical study, which shows how improved chunking reduces hallucinations. Agentic chunking improves answer completeness by 20–40% in A/B tests because semantically complete chunks reduce missing context.
Is chunking the only cause of hallucinations in RAG systems? No, chunking is not the only cause of hallucinations, but chunking is a primary contributing factor in retrieval failures. Hallucinations also result from coverage gaps where relevant chunks are not retrieved and from poor document parsing. Poor chunking amplifies these issues because fragmented chunks reduce the chance of retrieving correct information.
How does chunking quality reduce hallucinations? High-quality chunking reduces hallucinations by ensuring each chunk contains complete and meaningful context. High-quality chunking improves embedding accuracy, retrieval precision, and context completeness. High-quality chunking ensures the model receives sufficient evidence, which reduces the need to generate unsupported information.
Does Chunking Strategy Change Performance Across LLMs?
Yes, chunking strategy changes performance across LLMs because chunking controls the quality, structure, and completeness of the input context that every model receives. Chunking strategy impacts retrieval accuracy, which directly affects how any LLM generates responses. Chunking strategy influences performance regardless of the specific LLM because all models depend on retrieved context in RAG systems.
How does the chunking strategy affect LLM performance? The chunking strategy affects LLM performance by shaping retrieval quality and context relevance. The chunking strategy determines whether retrieved chunks contain complete or fragmented information. Chunking strategy improves retrieval accuracy by up to 9 percentage points, which directly improves answer quality across models.
Why does chunking matter even with strong LLMs? Chunking strategy matters because LLMs cannot compensate for missing or poorly structured context. The chunking strategy defines the input quality, and poor chunking leads to irrelevant answers up to 40% of the time. Chunking strategy impacts latency and cost because inefficient retrieval increases processing time, with reported cases reaching 8-second responses and high API costs.
Does chunking performance vary between different LLMs? Chunking strategy performance varies indirectly across LLMs because different models handle context length and reasoning differently. Larger context models tolerate bigger chunks, while smaller models require tighter chunking for precision. The chunking strategy must align with model constraints to maintain performance consistency.
What evidence exists about chunking vs LLM impact? The chunking strategy often has a greater impact on RAG performance than the choice of LLM in controlled experiments. Studies isolate chunking by keeping the generator model constant, which shows that performance differences come from chunking changes. The chunking strategy acts as the primary optimization layer before model selection.
Should chunk size differ between GPT, Claude, and open-source LLMs?
No, chunk size should not universally differ between GPT, Claude, and open-source LLMs because optimal chunk size depends on context limits, query type, and retrieval goals rather than model brand. Chunk size needs to align with how much context the model processes effectively, not just its maximum window. Chunk size optimization follows the same principles across models, even though context limits vary.
Why does chunk size not depend strictly on the LLM provider? Chunk size depends on effective context usage rather than maximum context window size. Larger context windows (Claude ~200k tokens, Gemini up to 1–2 million tokens) allow more text, but retrieval quality degrades when too much context is included. Research shows a context degradation point around 2,500 tokens, where response quality drops even in large-context models.
When should chunk size differ across models? Chunk size should differ when model context limits or retrieval setups impose constraints. Smaller-context models (GPT-3.5 at 4,096 tokens) require tighter chunking to avoid truncation. Larger-context models allow larger chunks, but chunk size still needs to stay within optimal retrieval ranges (256–1024 tokens).
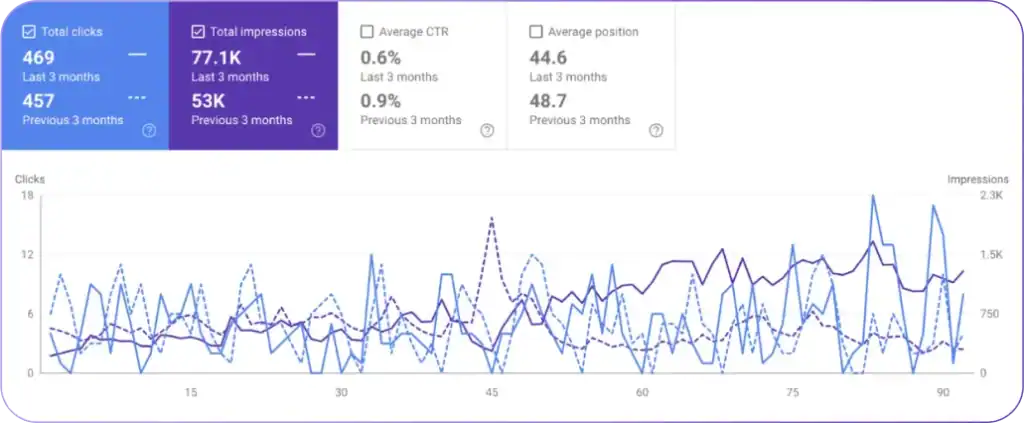
How do RAG systems affect chunk size across different LLMs? RAG systems standardize chunk size because retrieval pipelines operate independently of the generator model. Chunk size in RAG typically remains between 256–512 tokens for factual queries and 512–1024+ tokens for analytical queries. Chunk overlap (10–20%) ensures continuity regardless of the LLM used. For monitoring retrieval behavior and chunk effectiveness in production, LLM observability provides visibility into how chunks perform across queries and outputs.
What is the practical recommendation for chunk size across LLMs? Chunking best practices recommend starting with 400–512 tokens and adjusting based on retrieval performance, not model type. Chunk size should increase when context is missing and decrease when retrieval returns irrelevant information. Chunk size optimization remains consistent across GPT, Claude, and open-source LLMs because retrieval behavior drives performance.
Should chunking differ for dense vs sparse retrieval?
Yes, chunking should differ for dense vs sparse retrieval because each retrieval method relies on different matching mechanisms and information representation. Dense retrieval uses embeddings and benefits from semantically rich chunks, while sparse retrieval uses keyword matching and benefits from precise, term-focused chunks.
How does chunking differ for dense retrieval? Chunking for dense retrieval uses larger, context-rich chunks to improve semantic representation and similarity matching. Dense retrieval performs best with chunk sizes around 512–1024 tokens or page-level chunks because embeddings capture broader meaning. Chunk overlap RAG strategies (10–20%) improve precision by up to 14.5% because overlapping context strengthens semantic continuity.
How does chunking differ for sparse retrieval? Chunking for sparse retrieval uses smaller, keyword-focused chunks to improve exact term matching and indexing. Sparse retrieval relies on term frequency and lexical signals, so smaller chunks isolate keywords more effectively. Sparse retrieval benefits from minimal overlap because redundancy does not improve keyword matching.
Why do dense and sparse retrieval require different chunking strategies? Dense and sparse retrieval differ because one optimizes for semantic similarity while the other optimizes for lexical matching. Dense retrieval requires context to encode meaning, while sparse retrieval requires clean term boundaries. Chunking optimization must align with the retrieval type to maximize relevance and ranking performance.
What is the best practice for hybrid retrieval systems? Hybrid retrieval systems require balanced chunking that supports both semantic and keyword matching. Hybrid systems often use medium-sized chunks (256–512 tokens) with light overlap to support both retrieval methods. Hybrid chunking requires experimentation with chunk size, overlap, and ranking strategies to optimize performance.
What Does the Future of Chunking Strategies Look Like?
The future of chunking strategies focuses on adaptive, context-aware, and LLM-integrated methods that preserve meaning, improve retrieval accuracy, and reduce hallucinations in RAG systems. Chunking strategies are evolving beyond fixed-size segmentation toward intelligent systems that dynamically adjust based on document structure, query intent, and model capabilities.
What is Late Chunking, and how does it improve retrieval? Late Chunking is a chunking strategy that embeds entire documents before splitting them into chunks to preserve global context. Late Chunking generates token-level embeddings from full documents and then derives chunks, which ensures each chunk retains document-wide meaning. Late Chunking improves retrieval performance by 6.5 nDCG@10 points on long documents because cross-chunk relationships remain intact.
How does Agentic Chunking evolve chunking strategies? Agentic Chunking is a chunking strategy that uses LLM-driven decision-making to dynamically select and apply the best segmentation method. Agentic Chunking analyzes document structure and query intent to choose between semantic, structural, or page-level chunking. Agentic Chunking improves retrieval quality but increases computational cost due to multiple LLM calls.
What is Adaptive Chunking and why does it matter? Adaptive Chunking is a chunking strategy that dynamically adjusts chunk size and overlap based on content structure and semantic density. Adaptive Chunking achieved 87% accuracy compared to 13% for fixed-size chunking in a clinical study (p = 0.001). Adaptive Chunking improves performance because each chunk aligns with logical topic boundaries instead of arbitrary limits.
What roles do Hierarchical Chunking and Contextual Chunking with LLMs play? Hierarchical Chunking and Contextual Chunking with LLMs improve multi-level understanding and contextual enrichment in RAG systems. Hierarchical Chunking creates layered chunks that support both summary-level and detailed retrieval, achieving F1 scores around 0.80. Contextual Chunking with LLMs appends generated summaries or descriptions to chunks, which improves embedding quality and retrieval relevance.
How does Chunk Expansion improve retrieval context? Chunk Expansion is a retrieval strategy that adds neighboring chunks to increase contextual completeness at query time. Chunk Expansion retrieves adjacent segments (paragraphs, pages, sections), which ensures answers include surrounding information. Chunk Expansion improves answer completeness but increases token usage and cost.
How do increasing LLM context windows change chunking strategies? Increasing LLM context windows reduces the need for very small chunks but does not eliminate chunking as a retrieval mechanism. Large-context models support thousands to millions of tokens, which allows larger chunks or full documents. Chunking remains necessary because retrieval selects relevant subsets, reduces cost, and avoids the lost-in-the-middle problem.
How are chunking strategies evolving in RAG architectures? Chunking strategies are evolving toward multi-stage retrieval and agent-driven reasoning within RAG systems. Future systems retrieve large semantic units first and then perform fine-grained reasoning within those units. Chunking shifts from simple preprocessing to a core component of memory, reasoning, and cost optimization.
What challenges will shape the future of chunking? Future chunking strategies must address cost, consistency, reasoning complexity, and evaluation challenges. Larger contexts increase cost and latency, while multiple sources introduce conflicting information. Chunking strategies must integrate evaluation frameworks and observability to maintain performance at scale.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}